Sicherheit im Online-Gaming: Chaos Engineering mit DevOps-Praktiken kombinieren
Diese Seite wurde von PageTurner AI übersetzt (Beta). Nicht offiziell vom Projekt unterstützt. Fehler gefunden? Problem melden →

Die Interactive Entertainment Group (IEG) ist eine Abteilung von Tencent Holdings, die sich auf die Entwicklung von Online-Videospielen und anderen digitalen Inhalten wie Live-Streams konzentriert. Sie ist bekannt als Herausgeber einiger der beliebtesten Videospiele.
In diesem Artikel erkläre ich, warum und wie wir Chaos Engineering in unseren DevOps-Prozess eingeführt haben.
Täglich verarbeiten wir über 10.000.000 Besuche, in Spitzenzeiten über 1.000.000 Abfragen pro Sekunde (QPS). Um Spielern ein unterhaltsames Erlebnis zu bieten, starten wir tägliche und saisonale Spiel-Events. Manchmal bedeutet das über 500 Code-Updates pro Event am Tag. Mit wachsender Nutzerbasis vervielfacht sich die Datenmenge rapide – aktuell liegen wir bei 200 Terabyte. Die massiven Nutzeranfragen und schnellen Release-Zyklen meistern wir erfolgreich.
Eine cloud-native DevOps-Lösung entlastet unsere Event-Betreuer bei der wachsenden Anzahl von Online-Events. Unsere Pipeline übernimmt alles – vom Code-Schreiben bis zum Live-Schalten in Produktionsumgebungen: Erkennt die Plattform neuen Event-Code, erstellt sie automatisch Images und deployed sie auf Tencent Kubernetes Engine (TKE). Die gesamte Automatisierung dauert übrigens nur 5 Minuten.
Nahezu alle IEG-Betriebsdienste laufen mittlerweile auf TKE. Dank Cloud-native-Technologie ermöglicht elastisches Scaling schnellere Kapazitätsanpassungen.
Zusätzlich sollen Iterationen einfacher werden. Bewährte Praxis: Große, schwer wartbare Dienste in unabhängig verwaltbare "kleinere" Services aufteilen. Diese haben weniger Code, einfachere Logik und reduzierte Einarbeitungskosten. Wir setzen diese Microservice-Architektur in DevOps-Initiativen um. Doch mit steigender Service-Anzahl wächst die Komplexität ihrer Kommunikation. Schlimmer noch: Ein Ausfall eines "kleinen" Services kann eine Kettenreaktion auslösen – die Hölle der Microservice-Abhängigkeiten.
Die Fehlertoleranz variiert je nach Service: Manche unterstützen Downgrading, andere nicht. Hinzu kommen Services ohne zeitnahe Alarme oder effektive Debugging-Tools. Die Fehlersuche entwickelt sich zunehmend zum drängenden Problem im Arbeitsalltag.
Aber wir können das nicht ignorieren: Was, wenn instabile Leistung Spieler vertreibt? Was bei einem katastrophalen Ausfall?
Gezielte Störungen einsetzen
Netflix etablierte Chaos Engineering: Durch gezielte Fehlerinjektion in Nicht-Produktivumgebungen testet man die Systemresilienz für extreme Szenarien. Laut Gartner werden bis 2023 40% der Unternehmen Chaos Engineering nutzen, um DevOps-Ziele zu erreichen und ungeplante Ausfallzeiten um 20% zu reduzieren.
So vermeiden wir Worst-Case-Szenarien. Fehlerinjektion ist heute Pflicht für jedes Technikteam. In frühen Tests nahmen Entwickler Knoten vor Service-Starts bewusst offline, um Failover zu Disaster-Recovery-Systemen zu prüfen.
Doch Chaos Engineering geht über Fehlerinjektion hinaus. Es treibt ständig neue Techniken, professionelle Test-Tools und fundierte Theorien voran. Deshalb erforschen wir es weiter.
IEG hat sein Chaos-Engineering-Projekt vor über einem Jahr offiziell gestartet. Wir wollten es von Anfang an richtig machen. Entscheidend war die Auswahl eines Chaos-Engineering-Tools, das Experimente in Kubernetes-Umgebungen unterstützt. Nach sorgfältigem Vergleich sind wir überzeugt, dass Chaos Mesh die optimale Lösung für uns ist, weil:
-
Es handelt sich um ein Cloud Native Computing Foundation (CNCF)-Sandbox-Projekt mit einer aktiven und hilfsbereiten Community.
-
Es greift nicht in bestehende Anwendungen ein.
-
Es bietet eine Web-UI und vielfältige Fehlerinjektionstypen, wie im folgenden Bild dargestellt.
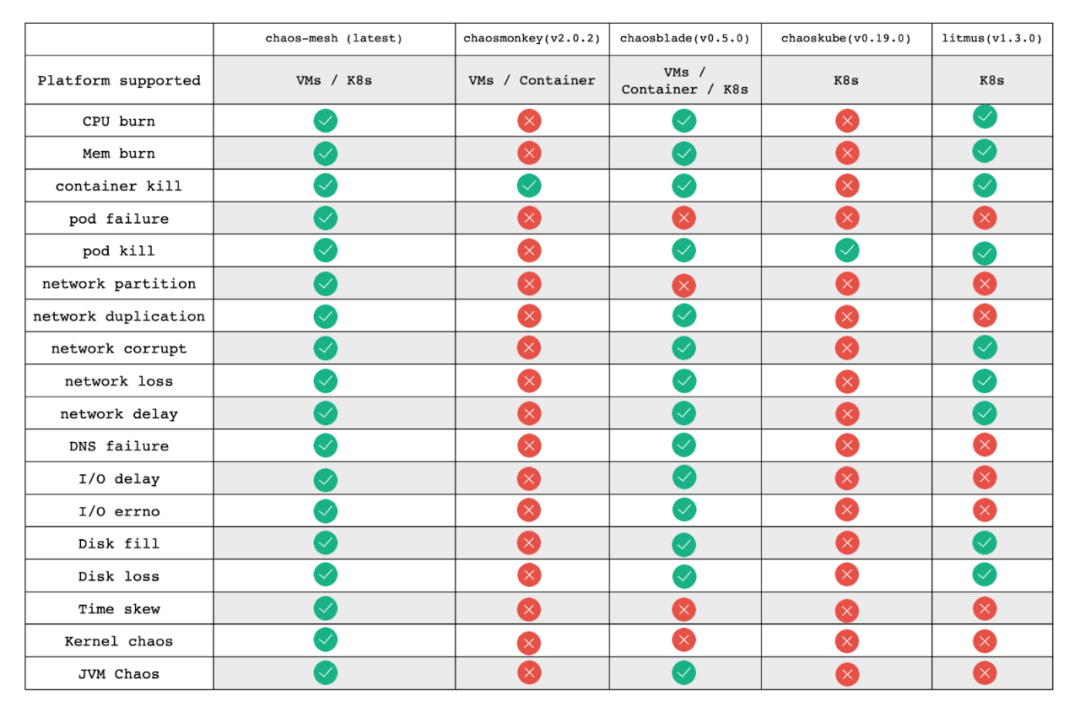
Hinweis: Dieser Vergleich ist veraltet und dient lediglich dazu, die von Chaos Mesh unterstützten Fehlerinjektionsfunktionen mit anderen bekannten Chaos-Engineering-Plattformen zu vergleichen. Es geht nicht um die Bevorzugung einzelner Projekte. Korrekturen sind willkommen.
Aufbau einer Chaos-Testplattform
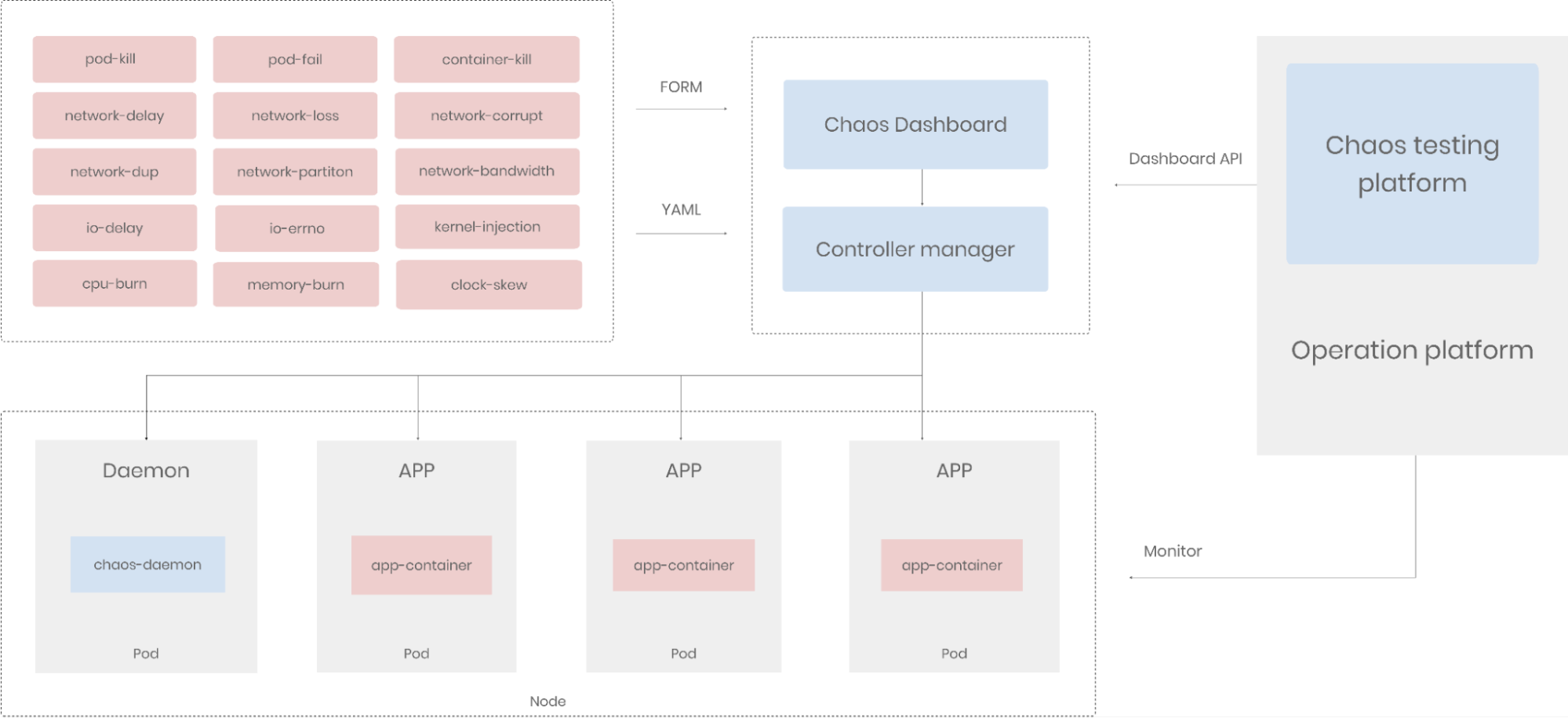
Unser Chaos-Engineering-Team hat Chaos Mesh in unsere CI/CD-Pipelines integriert. Wie unten dargestellt, spielt Chaos Mesh nun eine zentrale Rolle in unserer Betriebsplattform. Wir nutzen die Dashboard-API von Chaos Mesh, um Chaos-Experimente zu erstellen, auszuführen und zu löschen sowie sie auf unserer Plattform zu überwachen. Wir können grundlegende Systemfehler auf Pod-, Container-, Netzwerk- und IO-Ebene simulieren.
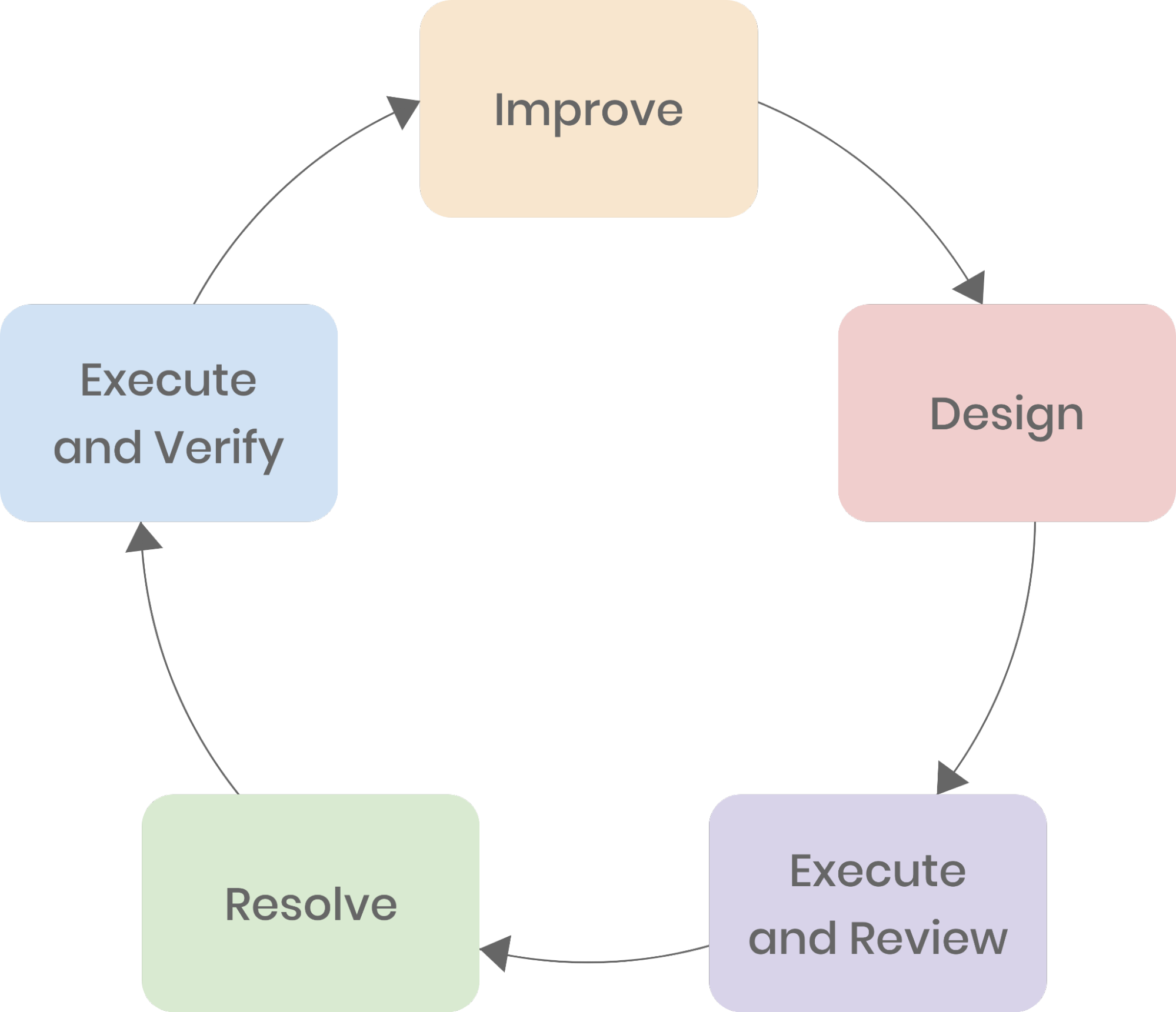
Bei IEG wird Chaos Engineering als Kreislauf mit mehreren Schlüsselphasen verstanden:
-
Systemresilienz verbessern
Eine anpassbare Chaos-Testplattform aufbauen.
-
Testplan erstellen
Der Plan muss Ziele, Umfang, einzuspritzende Fehler, Überwachungsmetriken etc. definieren. Experimente müssen kontrollierbar bleiben.
-
Chaos-Experimente durchführen und auswerten
Systemleistung vor und nach dem Experiment vergleichen.
-
Aufgetretene Probleme beheben
Identifizierte Schwachstellen beheben und System für Folgeexperimente optimieren.
-
Experimente wiederholen und Leistung verifizieren
Wiederholte Tests zeigen, ob die Systemleistung den Erwartungen entspricht. Bei Erfolg neuen Testplan erstellen.
Wir testen häufig die Leistung von Diensten unter hoher CPU-Auslastung. Nach Orchestrierung der Experimente überwachen wir die Leistungskennzahlen betroffener Dienste. Metriken wie QPS, Latenz und Erfolgsrate werden in Echtzeit auf der Betriebsplattform angezeigt. Abschließend generiert die Plattform Auswertungsberichte, um zu prüfen, ob die Experimente unsere Erwartungen erfüllt haben.
Anwendungsfälle
Folgende Beispiele zeigen, wie wir Chaos Engineering in unserem DevOps-Workflow einsetzen:
Höhere Granularität bei Fehlerinjektion
Statt ganze Systeme abzuschalten, injizieren wir gezielt Fehler – etwa Netzwerklatenz – in einzelne Spielerkonten. Durch Traffic-Hijacking und Experimente am Gateway erreichen wir diese präzise Steuerung.
Red Teaming
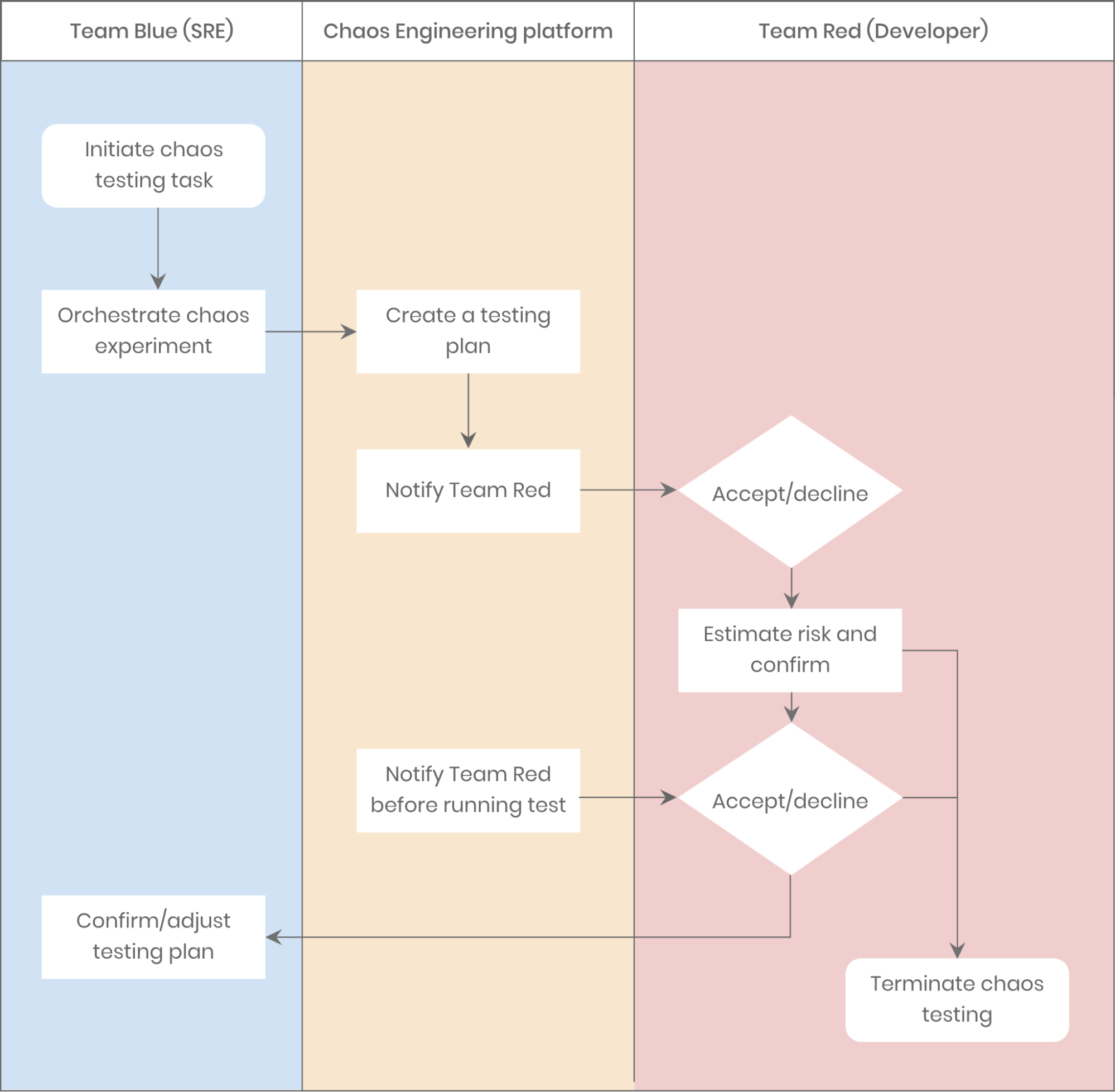
Verständlicherweise langweilten sich unsere Teammitglieder bei routinemäßigen Chaos-Experimenten. Letztendlich ist es vergleichbar damit, die linke Hand gegen die rechte kämpfen zu lassen. Bei IEG integrieren wir eine Testmethode namens Red Teaming in das Chaos Engineering, um die Systemresilienz auf organische Weise zu verbessern. Red Teaming ähnelt Penetrationstests, ist aber zielgerichteter. Dabei simulieren Tester reale Angriffe aus externer Perspektive. Wenn ich für den IT-Betrieb verantwortlich wäre, würde ich gezielt Fehler in bestimmten Diensten auslösen und prüfen, ob meine Entwicklerkollegen gute Arbeit leisten. Bei entdeckten Schwachstellen wäre eine "klare Ansage" fällig. Entwickler wiederum führen proaktiv Chaos-Experimente durch, um Risiken zu beseitigen und Kritik vorzubeugen.
Abhängigkeitsanalyse
Für Microservices ist das Management von Abhängigkeiten entscheidend. Bei uns dürfen nicht-kritische Dienste keine Engpässe für Kernservices verursachen. Glücklicherweise ermöglicht Chaos Engineering eine einfache Abhängigkeitsanalyse: Wir injizieren Fehler in aufgerufene Dienste und beobachten die Auswirkungen auf den Hauptdienst. Basierend auf den Ergebnissen optimieren wir die Dienstaufrufkette für spezifische Szenarien.
Automatisierte Fehlererkennung und -diagnose
Wir erforschen auch KI-Bots zur Fehlererkennung und -diagnose. Mit zunehmender Dienstekomplexität steigt die Ausfallwahrscheinlichkeit. Unser Ziel ist es, ein Fehlererkennungsmodell durch groß angelegte Chaos-Experimente in Produktionsumgebungen oder anderen kontrollierten Settings zu trainieren.
Chaos Engineering stärkt DevOps-Praktiken
Aktuell führen wöchentlich durchschnittlich über 50 Personen Chaos-Experimente durch – das sind mehr als 150 Tests, die insgesamt über 100 Probleme aufdecken.
Zeiten manueller Skripte für Fehlerinjektion sind vorbei, was besonders für Ungeübte mühsam war. Die Vorteile der Kombination von Chaos Engineering mit DevOps liegen auf der Hand: Innerhalb weniger Minuten lassen sich verschiedene Fehlertypen per Drag-and-Drop orchestrieren, mit einem Klick ausführen und Ergebnisse in Echtzeit überwachen – alles auf einer Plattform.
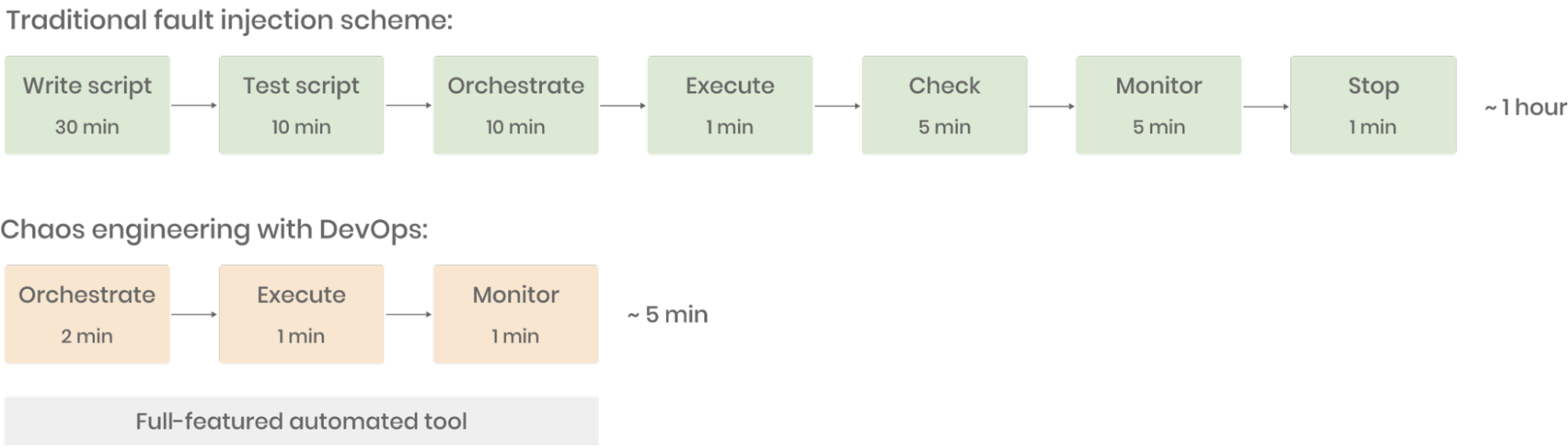
Dank ausgereifter Chaos-Engineering-Tools und optimierter DevOps-Prozesse hat sich die Effizienz von Fehlerinjektion und chaosbasierter Optimierung bei IEG in den letzten sechs Monaten mindestens verzehnfacht. Falls Sie noch Zweifel am Einsatz von Chaos Engineering haben, hoffe ich, dass unsere Erfahrungen hilfreich sind.