Chaos Mesh - Ihre Chaos-Engineering-Lösung für Systemresilienz auf Kubernetes

Diese Seite wurde von PageTurner AI übersetzt (Beta). Nicht offiziell vom Projekt unterstützt. Fehler gefunden? Problem melden →

Warum Chaos Mesh?
In der Welt des verteilten Rechnens können Fehler in Ihren Clustern jederzeit und überall unvorhersehbar auftreten. Traditionell setzen wir auf Unit- und Integrationstests, um die Produktionsreife eines Systems zu gewährleisten. Diese decken jedoch nur die Spitze des Eisbergs ab, wenn Cluster skalieren, Komplexitäten zunehmen und Datenvolumina im Petabyte-Bereich wachsen. Um Systemschwachstellen besser zu identifizieren und die Resilienz zu verbessern, entwickelte Netflix Chaos Monkey, das verschiedene Fehlertypen in Infrastruktur und Geschäftssysteme injiziert. So entstand das Chaos Engineering.
Bei PingCAP stehen wir vor demselben Problem bei der Entwicklung von TiDB, einer Open-Source-distributed-NewSQL-Datenbank. Fehlertoleranz bzw. Resilienz ist für uns besonders wichtig, da das wertvollste Gut jedes Datenbanknutzers - die Daten selbst - auf dem Spiel steht. Um Resilienz zu gewährleisten, haben wir frühzeitig damit begonnen, Chaos Engineering in unserem Testframework intern einzusetzen. Als TiDB jedoch wuchs, stiegen auch die Testanforderungen. Wir erkannten, dass wir eine universelle Chaos-Testing-Plattform benötigten - nicht nur für TiDB, sondern für verteilte Systeme allgemein.
Daher präsentieren wir Ihnen Chaos Mesh, eine cloud-native Chaos-Engineering-Plattform zur Orchestrierung von Chaos-Experimenten in Kubernetes-Umgebungen. Es handelt sich um ein Open-Source-Projekt, verfügbar unter https://github.com/chaos-mesh/chaos-mesh.
In den folgenden Abschnitten erläutere ich, was Chaos Mesh ist, wie wir es konzipiert und implementiert haben, und zeige Ihnen anschließend, wie Sie es in Ihrer Umgebung nutzen können.
Was kann Chaos Mesh?
Chaos Mesh ist eine vielseitige Chaos-Engineering-Plattform mit umfassenden Methoden zur Fehlerinjektion für komplexe Systeme auf Kubernetes, die Fehler in Pods, Netzwerken, Dateisystemen und sogar im Kernel abdeckt.
Hier ein Beispiel, wie wir mit Chaos Mesh einen Systemfehler in TiDB lokalisiert haben: Wir simulierten Pod-Ausfälle in unserer verteilten Speicherengine (TiKV) und beobachteten die Änderungen bei den Queries per Second (QPS). Normalerweise sollte die QPS nach einem TiKV-Knotenausfall kurzzeitig schwanken, bevor sie wieder auf das Niveau vor dem Fehler zurückkehrt. So gewährleisten wir Hochverfügbarkeit.
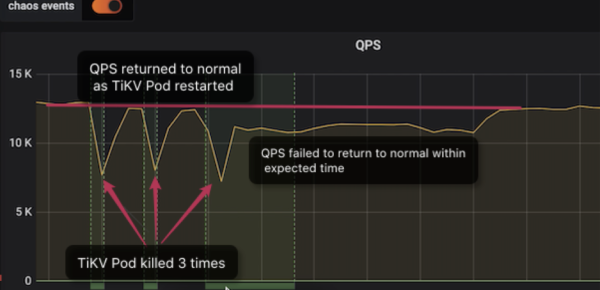
Wie im Dashboard zu sehen ist:
-
Bei den ersten beiden Ausfällen normalisiert sich die QPS nach etwa 1 Minute.
-
Nach dem dritten Ausfall dauert die Wiederherstellung jedoch deutlich länger - etwa 9 Minuten. Ein derart langer Ausfall ist unerwartet und würde sich definitiv auf Online-Dienste auswirken.
Nach der Diagnose stellten wir fest, dass die getestete TiDB-Clusterversion (V3.0.1) Probleme bei der Behandlung von TiKV-Ausfällen aufwies. Diese Probleme haben wir in späteren Versionen behoben.
Chaos Mesh kann jedoch weit mehr als nur Ausfälle simulieren. Es umfasst diese Fehlerinjektionsmethoden:
-
pod-kill: Simuliert das gezielte Beenden von Kubernetes-Pods
-
pod-failure: Simuliert kontinuierliche Nichtverfügbarkeit von Kubernetes-Pods
-
network-delay: Simuliert Netzwerkverzögerungen
-
network-loss: Simuliert Paketverluste im Netzwerk
-
network-duplication: Simuliert Netzwerkpaket-Duplikation
-
network-corrupt: Simuliert Netzwerkpaket-Korruption
-
network-partition: Simuliert Netzwerkpartitionierung
-
I/O delay: Simuliert Dateisystem-I/O-Verzögerungen
-
I/O errno: Simuliert Dateisystem-I/O-Fehler
Designprinzipien
Chaos Mesh wurde nach drei Kernprinzipien entworfen: Einfache Bedienung, Skalierbarkeit und Kubernetes-Optimierung.
Einfache Bedienung
Für eine niedrige Einstiegshürde muss Chaos Mesh:
-
Ohne spezielle Abhängigkeiten auskommen und direkt auf Kubernetes-Clustern einschließlich Minikube deploybar sein
-
Ohne Anpassungen an der Bereitstellungslogik des zu testenden Systems (SUT) auskommen, um Chaos-Experimente in Produktionsumgebungen durchführen zu können
-
Einfache Orchestrierung von Fehlerinjektionen ermöglichen sowie klare Sichtbarkeit von Experimentstatus und -ergebnissen bieten, inklusive schnellem Rollback von Fehlern
-
Implementierungsdetails abstrahieren, damit sich Nutzer voll auf die Chaos-Experimente konzentrieren können
Skalierbarkeit
Chaos Mesh soll erweiterbar sein, um neue Anforderungen modular integrieren zu können ohne ständige Neuentwicklungen. Konkret bedeutet dies:
-
Wiederverwendung existierender Implementierungen, um Fehlerinjektionsmethoden einfach skalieren zu können
-
Einfache Integration mit anderen Testframeworks
Für Kubernetes entwickelt
In der Containerwelt ist Kubernetes der unangefochtene Leader. Seine Adaptionsrate übertrifft alle Erwartungen und es hat den Orchestrierungskrieg gewonnen. Im Kern ist Kubernetes ein Betriebssystem für die Cloud.
TiDB ist eine cloud-native Distributed Database. Unsere interne Testplattform läuft seit Beginn auf Kubernetes. Täglich betreiben wir hunderte TiDB-Cluster auf Kubernetes für diverse Tests – einschließlich umfangreicher Chaos-Experimente, die Produktionsausfälle simulieren. Die Kombination von Chaos Engineering und Kubernetes war daher eine natürliche Wahl und Kernprinzip unserer Implementierung.
CustomResourceDefinitions-Design
Chaos Mesh nutzt CustomResourceDefinitions (CRD) zur Definition von Chaos-Objekten. Im Kubernetes-Ökosystem ist CRD eine ausgereifte Lösung für benutzerdefinierte Ressourcen mit umfangreichen Toolsets. Diese Integration macht Chaos Mesh nativer Bestandteil der Kubernetes-Welt.
Statt alle Fehlerinjektionstypen in einem einheitlichen CRD-Objekt abzubilden, nutzen wir separate CRD-Objekte für verschiedene Fehlertypen. Neue Injektionsmethoden werden entweder bestehenden CRDs hinzugefügt oder erhalten eigene CRDs. Dieses Design sorgt dafür, dass Chaos-Objektdefinitionen und Implementierungslogik auf oberster Ebene extrahiert werden, was die Codestruktur klarer macht. Dieser Ansatz reduziert auch den Grad der Kopplung und die Fehlerwahrscheinlichkeit. Darüber hinaus ist Kubernetess controller-runtime eine hervorragende Wrapper-Implementierung für Controller. Das spart uns viel Zeit, da wir nicht für jedes CRD-Projekt wiederholt denselben Satz von Controllern implementieren müssen.
-
Klare Code-Struktur durch Entkopplung der Chaos-Objektdefinitionen von der Implementierungslogik
-
Geringere Kopplung und Fehleranfälligkeit
Mit klar definierten Aktionen wie pod-kill kann uns PodChaos helfen, solche Probleme effektiver zu identifizieren. Das PodChaos-Objekt verwendet folgenden Code:
spec:
action: pod-kill
mode: one
selector:
namespaces:
- tidb-cluster-demo
labelSelectors:
"app.kubernetes.io/component": "tikv"
scheduler:
cron: "@every 2m"
Chaos Mesh implementiert derzeit PodChaos, NetworkChaos und IOChaos – die Namen spiegeln direkt die jeweiligen Fehlerkategorien wider.
-
Das
action-Attribut definiert den spezifischen Fehlertyp, der injiziert werden soll. Im Fall vonpod-killwerden Pods zufällig terminiert. -
Das
selector-Attribut begrenzt den Umfang des Chaos-Experiments auf einen bestimmten Bereich. In diesem Fall gilt der Bereich für TiKV-Pods im TiDB-Cluster mit demtidb-cluster-demo-Namespace. -
Das
scheduler-Attribut definiert das Intervall für jede Chaos-Fehleraktion.
Weitere Details zu CRD-Objekten wie NetworkChaos und IOChaos finden Sie in der Chaos-mesh-Dokumentation.
Wie funktioniert Chaos Mesh?
Nachdem wir das CRD-Design geklärt haben, werfen wir einen Blick auf das Gesamtbild der Funktionsweise von Chaos Mesh. Dabei sind folgende Hauptkomponenten beteiligt:
-
controller-manager
Fungiert als "Gehirn" der Plattform. Er verwaltet den Lebenszyklus von CRD-Objekten und plant Chaos-Experimente. Er enthält Objekt-Controller für die Planung von CRD-Objektinstanzen, während der admission-webhooks-Controller dynamisch Sidecar-Container in Pods injiziert.
-
chaos-daemon
Läuft als privilegierter DaemonSet und kann Netzwerkgeräte auf dem Knoten sowie Cgroups steuern.
-
sidecar
Wird als spezieller Containertyp ausgeführt, der dynamisch durch admission-webhooks in den Ziel-Pod injiziert wird. Beispielsweise führt der
chaosfs-Sidecar-Container einen Fuse-Daemon aus, um die I/O-Operationen des Anwendungscontainers zu übernehmen.
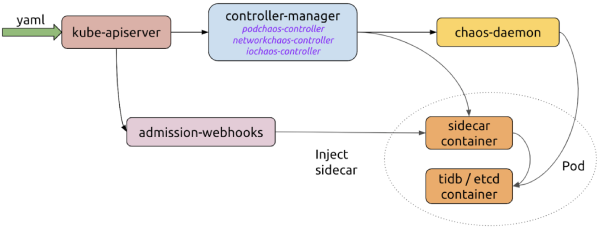
So optimieren diese Komponenten den Ablauf eines Chaos-Experiments:
-
Der Benutzer erstellt oder aktualisiert Chaos-Objekte über eine YAML-Datei oder einen Kubernetes-Client im Kubernetes-API-Server.
-
Chaos Mesh überwacht die Chaos-Objekte über den API-Server und verwaltet den Lebenszyklus von Chaos-Experimenten durch Erstellungs-, Aktualisierungs- oder Löschungsereignisse. Dabei arbeiten controller-manager, chaos-daemon und Sidecar-Container zusammen, um Fehler zu injizieren.
-
Wenn admission-webhooks eine Pod-Erstellungsanfrage erhält, wird das zu erstellende Pod-Objekt dynamisch aktualisiert – beispielsweise durch Injektion des Sidecar-Containers.
Chaos in Aktion
Die vorherigen Abschnitte haben Design und Funktionsweise von Chaos Mesh erläutert. Kommen wir nun zur Praxis und zeigen Ihnen, wie Sie Chaos Mesh einsetzen können. Beachten Sie, dass die Testdauer je nach Komplexität der Anwendung und den in der CRD definierten Testplanungsregeln variiert.
Umgebung vorbereiten
Chaos Mesh läuft auf Kubernetes v1.12 oder höher. Helm, ein Kubernetes-Paketverwaltungstool, übernimmt die Bereitstellung und Verwaltung von Chaos Mesh. Stellen Sie vor der Ausführung sicher, dass Helm im Kubernetes-Cluster ordnungsgemäß installiert ist. Gehen Sie wie folgt vor:
-
Stellen Sie sicher, dass ein Kubernetes-Cluster vorhanden ist. Falls ja, fahren Sie mit Schritt 2 fort; andernfalls starten Sie lokal einen Cluster mit dem von Chaos Mesh bereitgestellten Skript:
// install kind
curl -Lo ./kind https://github.com/kubernetes-sigs/kind/releases/download/v0.6.1/kind-$(uname)-amd64
chmod +x ./kind
mv ./kind /some-dir-in-your-PATH/kind
// get script
git clone https://github.com/chaos-mesh/chaos-mesh
cd chaos-mesh
// start cluster
hack/kind-cluster-build.shHinweis: Das lokale Starten von Kubernetes-Clustern beeinflusst netzwerkbezogene Fehlerinjektionen.
-
Falls Ihr Kubernetes-Cluster bereit ist, verwenden Sie Helm und Kubectl, um Chaos Mesh zu installieren:
git clone https://github.com/chaos-mesh/chaos-mesh.git
cd chaos-mesh
// create CRD resource
kubectl apply -f manifests/
// install chaos-mesh
helm install helm/chaos-mesh --name=chaos-mesh --namespace=chaos-meshWarten Sie, bis alle Komponenten installiert sind, und prüfen Sie den Installationsstatus mit:
// check chaos-mesh status
kubectl get pods --namespace chaos-mesh -l app.kubernetes.io/instance=chaos-meshWenn die Installation erfolgreich war, sehen Sie alle Pods im laufenden Zustand. Jetzt kann es losgehen.
Sie können Chaos Mesh entweder über eine YAML-Definition oder die Kubernetes-API ausführen.
Chaos mit einer YAML-Datei ausführen
Sie können eigene Chaos-Experimente über die YAML-Datei-Methode definieren, die einen schnellen, komfortablen Weg bietet, um Chaos-Experimente nach dem Deployment Ihrer Anwendung durchzuführen. Gehen Sie folgendermaßen vor:
Hinweis: Zur Veranschaulichung verwenden wir TiDB als Testsystem. Sie können ein beliebiges Zielsystem verwenden und die YAML-Datei entsprechend anpassen.
-
Stellen Sie einen TiDB-Cluster namens
chaos-demo-1bereit. Hierfür können Sie den TiDB Operator verwenden. -
Erstellen Sie die YAML-Datei
kill-tikv.yamlmit folgendem Inhalt:apiVersion: chaos-mesh.org/v1alpha1
kind: PodChaos
metadata:
name: pod-kill-chaos-demo
namespace: chaos-mesh
spec:
action: pod-kill
mode: one
selector:
namespaces:
- chaos-demo-1
labelSelectors:
'app.kubernetes.io/component': 'tikv'
scheduler:
cron: '@every 1m' -
Speichern Sie die Datei.
-
Starten Sie das Chaos-Experiment mit
kubectl apply -f kill-tikv.yaml.
Dieses Experiment simuliert das häufige Abstürzen von TiKV-Pods im Cluster chaos-demo-1:
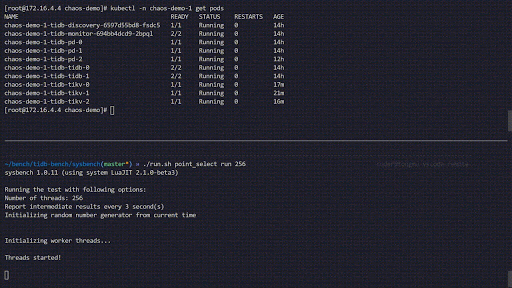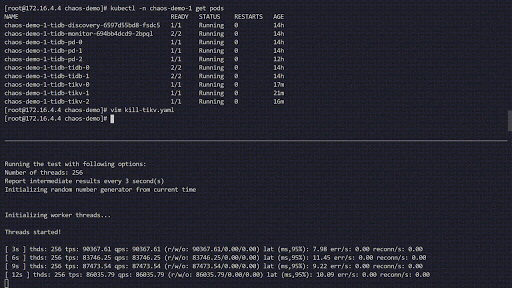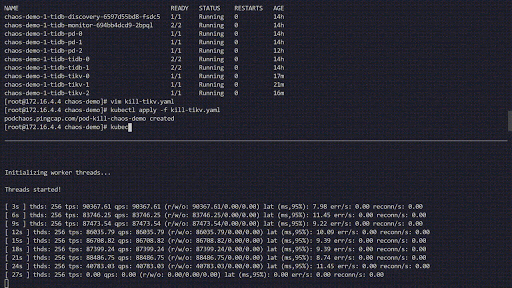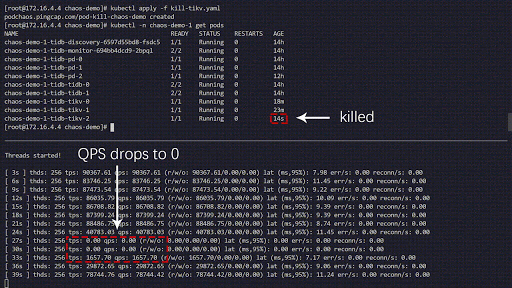
Wir nutzen ein sysbench-Programm, um die Echtzeit-Änderungen der QPS (Queries per Second) im TiDB-Cluster zu überwachen. Bei Fehlerinjektion zeigt die QPS deutliche Schwankungen, was bedeutet, dass ein TiKV-Pod gelöscht wurde und Kubernetes anschließend einen neuen Pod erstellt.
Weitere YAML-Beispiele finden Sie unter https://github.com/chaos-mesh/chaos-mesh/tree/master/examples.
Chaos mit der Kubernetes-API ausführen
Da Chaos Mesh CRDs zur Definition von Chaos-Objekten nutzt, können Sie diese direkt über die Kubernetes-API steuern. Dies ermöglicht die einfache Integration in eigene Anwendungen mit maßgeschneiderten Testszenarien und automatisierten Chaos-Experimenten.
Im test-infra-Projekt simulieren wir Fehler in etcd-Clustern auf Kubernetes, darunter Node-Neustarts, Netzwerkausfälle und Dateisystemfehler.
Nachfolgend sehen Sie ein Beispielskript für Chaos Mesh mit der Kubernetes-API:
import (
"context"
"github.com/chaos-mesh/chaos-mesh/api/v1alpha1"
"sigs.k8s.io/controller-runtime/pkg/client"
)
func main() {
// ...
delay := &chaosv1alpha1.NetworkChaos{
Spec: chaosv1alpha1.NetworkChaosSpec{
// ...
},
}
k8sClient := client.New(conf, client.Options{ Scheme: scheme.Scheme })
k8sClient.Create(context.TODO(), delay)
k8sClient.Delete(context.TODO(), delay)
}
Was bringt die Zukunft?
In diesem Artikel haben wir Ihnen Chaos Mesh vorgestellt, unsere Open-Source-Chaos-Engineering-Plattform für Cloud-Native-Umgebungen. Es gibt noch viele laufende Entwicklungen, mit weiteren Details zu Design, Anwendungsfällen und Weiterentwicklung. Bleiben Sie gespannt.
Die Open-Source-Veröffentlichung ist erst der Anfang. Zusätzlich zu den in früheren Abschnitten vorgestellten Chaos-Experimenten auf Infrastrukturebene arbeiten wir daran, eine breitere Palette feiner granulärer Fehlertypen zu unterstützen, wie zum Beispiel:
-
Einspritzen von Fehlern auf Systemaufruf- und Kernel-Ebene mithilfe von eBPF und anderen Tools
-
Einspritzen spezifischer Fehlertypen auf Anwendungsfunktions- und Anweisungsebene durch Integration von failpoint, wodurch Szenarien abgedeckt werden, die mit herkömmlichen Injektionsmethoden unmöglich wären
Zukünftig werden wir das Chaos Mesh Dashboard kontinuierlich verbessern, sodass Benutzer leicht erkennen können, ob und wie ihre Online-Services durch Fehlerinjektionen beeinträchtigt werden. Darüber hinaus umfasst unsere Roadmap eine benutzerfreundliche Schnittstelle zur Fehlerorchestrierung. Wir planen weitere spannende Funktionen wie Chaos Mesh Verifier und Chaos Mesh Cloud.
Wenn Sie eines dieser Vorhaben interessant finden, helfen Sie uns mit, eine weltklasse Chaos-Engineering-Plattform zu bauen. Mögen unsere Anwendungen im Chaos auf Kubernetes tanzen!
Wenn Sie einen Fehler entdecken oder etwas vermissen, können Sie gerne ein Issue erstellen, einen PR öffnen oder uns im #project-chaos-mesh-Kanal im CNCF Slack kontaktieren.