Tägliche Berichterstattung für Chaos-Testergebnisse entwickeln

Diese Seite wurde von PageTurner AI übersetzt (Beta). Nicht offiziell vom Projekt unterstützt. Fehler gefunden? Problem melden →

Chaos Mesh ist eine cloud-native Chaos-Engineering-Plattform, die Chaos-Experimente in Kubernetes-Umgebungen orchestriert. Sie ermöglicht es Ihnen, die Resilienz Ihres Systems zu testen, indem Probleme wie Netzwerkfehler, Dateisystemfehler und Pod-Fehler simuliert werden. Nach jedem Chaos-Experiment können Sie die Testergebnisse durch Überprüfung der Logs einsehen. Dies ist jedoch weder direkt noch effizient. Daher habe ich ein tägliches Berichtssystem entwickelt, das automatisch Logs analysiert und Berichte generiert. So lassen sich Probleme einfach identifizieren.
In diesem Artikel gebe ich Ihnen Einblicke in den Aufbau eines solchen Berichtssystems sowie in die während der Entwicklung aufgetretenen Probleme und deren Lösungen.
Chaos Mesh auf Kubernetes bereitstellen
Chaos Mesh ist für Kubernetes konzipiert – ein wesentlicher Grund, warum es Nutzern ermöglicht, Fehler in Dateisystemen, Pods oder Netzwerken für spezifische Anwendungen zu injizieren.
Frühere Dokumentationen beschrieben zwei Methoden zur schnellen Bereitstellung eines virtuellen Kubernetes-Clusters auf Ihrem Rechner: kind und minikube. Normalerweise genügt ein Einzeilen-Befehl, um einen Kubernetes-Cluster bereitzustellen und Chaos Mesh zu installieren. Dabei treten jedoch folgende Probleme auf:
-
Lokal gestartete Kubernetes-Cluster beeinträchtigen netzwerkbezogene Fehlertypen.
-
Nutzer in China können extrem langsame Docker-Image-Pulls oder Timeouts erleben.
Bei der Bereitstellung eines Kubernetes-Clusters mit kind sind alle Knoten virtuelle Maschinen (VMs). Dies erschwert Offline-Image-Pulls. Als Lösung können Sie den Kubernetes-Cluster auf mehreren physischen Maschinen bereitstellen, wobei jede als Worker Node fungiert. Beschleunigen Sie den Image-Pull-Prozess mit dem Befehl docker load, um benötigte Images vorab zu laden. Zusätzlich installieren Sie kubectl und Helm gemäß der Dokumentation.
Hinweis: Aktuelle Installationsanleitungen finden Sie unter Chaos Mesh Quick Start.
TiDB bereitstellen
Der nächste Schritt ist die Bereitstellung von TiDB auf Kubernetes. Ich nutzte TiDB Operator zur Vereinfachung. Details finden Sie unter Get started with TiDB Operator in Kubernetes.
Zwei Punkte sind hier besonders hervorzuheben:
-
Installieren Sie zunächst Custom Resource Definitions (CRDs) für TiDB Operator-Komponenten. Andernfalls treten bei der Installation Fehler auf.
-
Verwenden Sie Longhorn, ein verteiltes Block-Speichersystem für Kubernetes, um lokale Persistent Volumes (PVs) für Ihren Cluster zu erstellen. So müssen PVs nicht manuell vorab erstellt werden: Bei jedem Pod-Pull wird automatisch ein PV erstellt und gemountet.
Das größte Problem war extrem langsame Image-Pulls während der Dienstbereitstellung. Bei virtuellen Maschinen in Ihrem Kubernetes-Cluster laden Sie benötigte Images vorab auf jede Maschine:
## Pull required images on a machine with a good network connection
docker pull pingcap/tikv:latest
docker pull pingcap/tidb:latest
docker pull pingcap/pd:latest
## Export images and save them to each machine in the Kubernetes cluster
docker save -o tikv.tar pingcap/tikv:latest
docker save -o tidb.tar pingcap/tidb:latest
docker save -o pd.tar pingcap/pd:latest
## Load images to each machine
docker load < tikv.tar
docker load < tidb.tar
docker load < pd.tar
Mit diesen Befehlen nutzen Sie Images aus der lokalen Docker-Registry zur Bereitstellung des neuesten TiDB-Clusters – ohne Remote-Repository-Pulls. Dieses Vorgehen gilt auch für die Chaos-Mesh-Installation. Bei unbekannten benötigten Images starten Sie die Chaos-Mesh-Installation via Helm und überprüfen Sie mit kubectl describe:
## Check pods that are deployed in a specific namespace.
kubectl describe pods -n tidb-test
Das Herunterladen der Images dauert normalerweise am längsten. Wenn der Pod gerade auf einem Node eingeplant wird, überprüfen Sie ihn später.
Chaos-Experiment durchführen
Um ein Chaos-Experiment zu starten, müssen Sie es zunächst über YAML-Dateien definieren und mit kubectl apply ausführen. In diesem Beispiel habe ich ein Chaos-Experiment mit PodChaos erstellt, um einen Pod-Absturz zu simulieren. Detaillierte Anweisungen finden Sie unter Chaos-Experiment durchführen.
Täglichen Bericht erstellen
Logs sammeln
Bei Chaos-Experimenten in TiDB-Clustern treten typischerweise viele Fehler auf. Um diese Fehlerprotokolle zu sammeln, führen Sie den Befehl kubectl logs aus:
kubectl logs <podname> -n tidb-test --since=24h >> tidb.log
Alle in den letzten 24 Stunden generierten Logs des betreffenden Pods im Namespace tidb-test werden in der Datei tidb.log gespeichert.
Fehler und Warnungen filtern
In diesem Schritt müssen Sie Fehler- und Warnmeldungen aus den Logs extrahieren. Hier bieten sich zwei Optionen:
-
Verwenden Sie Textverarbeitungstools wie awk. Dies setzt fundierte Kenntnisse von Linux/Unix-Befehlen voraus.
-
Schreiben Sie ein Skript. Wenn Sie mit Linux/Unix-Befehlen nicht vertraut sind, ist dies die bessere Wahl.
Diagramm erstellen
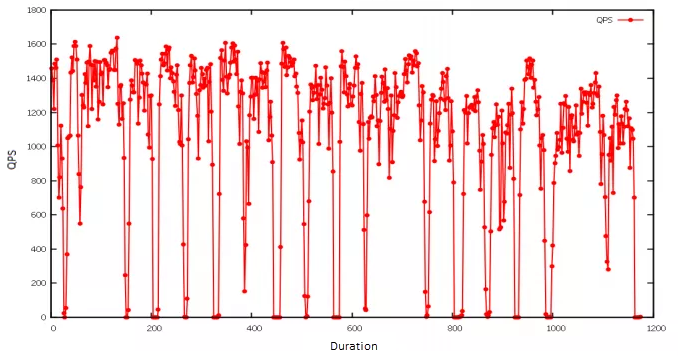
Für die Visualisierung habe ich gnuplot verwendet, ein Linux-Kommandozeilen-Tool zur Diagrammerstellung. Im folgenden Beispiel importierte ich die Ergebnisse des Lasttests und erstellte ein Liniendiagramm, das zeigt, wie sich die Queries pro Sekunde (QPS) veränderten, als ein bestimmter Pod nicht verfügbar war. Da das Chaos-Experiment periodisch ausgeführt wurde, zeigte die QPS-Anzahl ein charakteristisches Muster: Sie sank abrupt und erholte sich dann schnell wieder auf den Normalwert.
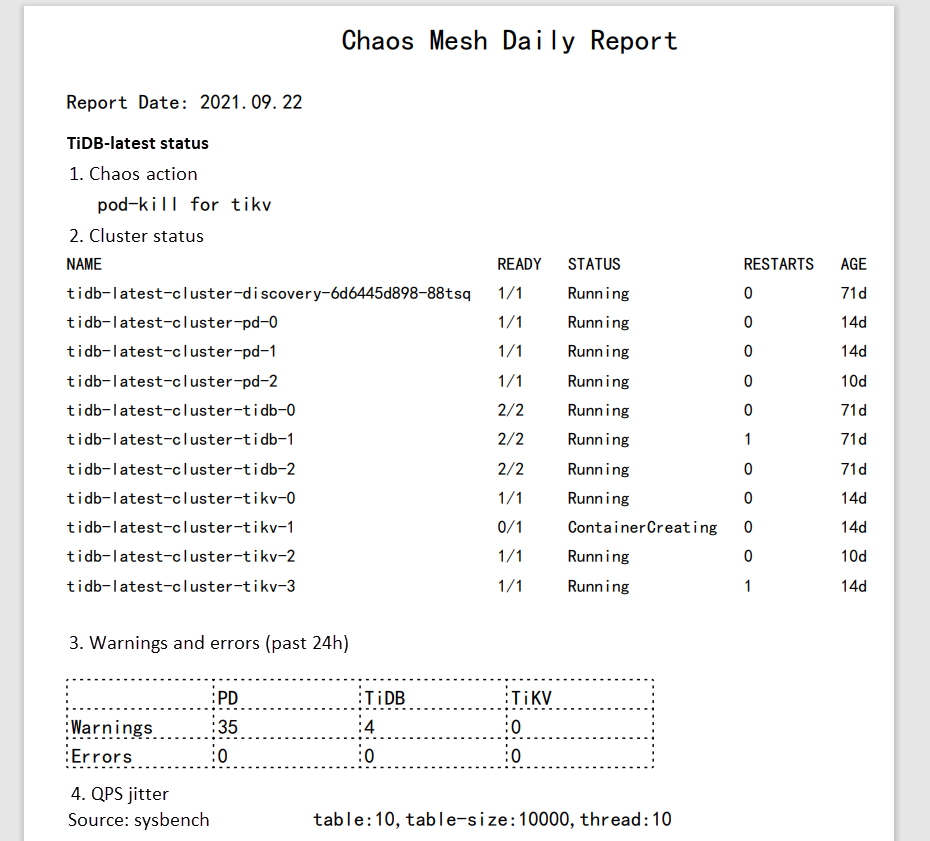
Bericht als PDF generieren
Derzeit gibt es keine API zur Erstellung von Chaos Mesh-Berichten oder zur Ergebnisanalyse. Ich entschied mich für PDF-Berichte, da sie in verschiedenen Browsern konsistent lesbar sind. Dazu verwendete ich gopdf, eine Bibliothek zur PDF-Generierung, die das Einfügen von Bildern und Tabellen ermöglicht – perfekt für meine Anforderungen.
Für tägliche Berichte nutzte ich crond, um die Befehle jeden Morgen automatisch auszuführen. So lag bei Arbeitsbeginn stets ein aktueller Bericht bereit.
Webanwendung für die tägliche Berichterstattung entwickeln
Um Berichte besser zugänglich zu machen, entwickelte ich eine Webanwendung. Ursprünglich wollte ich eine Backend-API für die Generierungszeitpunkte implementieren, doch der Aufwand erschien unverhältnismäßig. Die entscheidenden Informationen stehen bereits im Dateinamen – beispielsweise report-2021-07-09-bad.pdf signalisiert Handlungsbedarf. Diese Vereinfachung reduziert Komplexität erheblich.
Zukünftig sind Verbesserungen bei Backend-Schnittstellen und Berichtsinhalten geplant. Aber für den Anfang genügt ein zuverlässiges tägliches Berichtssystem.
Ich setzte Vue.js mit der UI-Bibliothek antd um. Automatisch generierte Berichte speichere ich im static-Ordner, sodass die Webanwendung sie direkt rendern kann. Details finden Sie unter antd mit vue-cli 3 verwenden.
Das Beispiel zeigt eine Webanwendung zur täglichen Berichtsanzeige. Rote Karten signalisieren, dass ein Testbericht aufgrund aufgetretener Fehler überprüft werden sollte.

Durch Anklicken der roten Karte öffnet sich der Bericht, wie unten dargestellt. Ich habe pdf.js zur Anzeige der PDF verwendet.
Zusammenfassung
Chaos Mesh ermöglicht die Simulation von Fehlern, die cloud-native Anwendungen häufig begegnen. In diesem Artikel habe ich ein PodChaos-Experiment erstellt und beobachtet, wie die QPS im TiDB-Cluster beeinträchtigt wurde, wenn der Pod nicht verfügbar war. Durch Protokollanalyse kann ich die Robustheit und Hochverfügbarkeit des Systems verbessern. Ich entwickelte eine Webanwendung zur Generierung täglicher Berichte für Fehlerbehebung und Debugging. Sie können die Berichte auch nach Ihren Anforderungen anpassen.
Unser Team arbeitet ebenfalls an einem Projekt zur Kompatibilität von TiDB mit PostgreSQL. Wenn Sie Interesse haben und Beiträge leisten möchten, können Sie gerne ein Issue auswählen und beginnen.
Ursprünglich veröffentlicht bei The New Stack.