Sécuriser les jeux en ligne : Associer l’ingénierie du chaos aux pratiques DevOps
Cette page a été traduite par PageTurner AI (bêta). Non approuvée officiellement par le projet. Vous avez trouvé une erreur ? Signaler un problème →

L'Interactive Entertainment Group (IEG) est une division de Tencent Holdings spécialisée dans le développement de jeux vidéo en ligne et de contenus numériques tels que les diffusions en direct. Elle est connue pour être l'éditeur de certains des jeux vidéo les plus populaires.
Dans cet article, j'expliquerai pourquoi et comment nous avons intégré l'ingénierie du chaos dans notre processus DevOps.
Chaque jour, nous traitons plus de 10 000 000 de visites au total et, pendant les heures de pointe, nous gérons plus de 1 000 000 de requêtes par seconde (QPS). Pour garantir aux joueurs une expérience divertissante et immersive, nous lançons divers événements quotidiens ou saisonniers. Parfois, cela signifie que nous devons mettre à jour le code des événements plus de 500 fois par jour. À mesure que notre base d'utilisateurs croît, le volume total de données augmente rapidement. Actuellement, ce chiffre atteint 200 téraoctets. Nous devons gérer d'énormes volumes de requêtes et des cycles de mise en production rapides, et nous y parvenons avec succès.
Une solution DevOps cloud native libère nos opérateurs d'événements face à la multiplication des événements en ligne. Nous avons développé un pipeline qui prend en charge toutes leurs tâches, de l'écriture du code au déploiement des événements en production : dès que de nouveaux codes d'événement sont détectés, la plateforme opérationnelle construit automatiquement des images et les déploie sur Tencent Kubernetes Engine (TKE). Vous vous demandez peut-être combien de temps prend ce processus automatisé : seulement 5 minutes.
Actuellement, presque tous les services opérationnels de l'IEG s'exécutent sur TKE. Grâce à la technologie cloud native, la mise à l'échelle élastique permet un ajustement plus rapide des capacités des services cloud.
De plus, nous souhaitons simplifier les cycles de mise en production. Une bonne pratique consiste à décomposer les services volumineux et complexes en nombreux services « plus petits » que nous pouvons maintenir indépendamment. Ces services « petits » ont moins de code et une logique plus simple, avec des coûts de transfert et de formation réduits. En tant que développeurs, nous adoptons cette architecture de microservices dans le cadre de nos initiatives DevOps. Pourtant, des problèmes similaires persistent. À mesure que le nombre de services augmente, la complexité des appels entre eux s'accroît. Pire encore, si un service « petit » tombe en panne, il peut déclencher une réaction en chaîne faisant tomber tous les services — un enfer de dépendances des microservices.
Le problème est que la tolérance aux pannes varie selon les services. Certains supportent la dégradation, d'autres non. Sans compter que certains services ne fournissent pas d'alertes rapides ou manquent d'outils de débogage efficaces. Résultat, le débogage des services est devenu un problème délicat et de plus en plus urgent dans notre travail quotidien.
Mais nous ne pouvons pas rester les bras croisés. Et si les performances instables éloignent constamment nos joueurs ? Et si une défaillance catastrophique survenait ?
Que viennent les pannes
Netflix a introduit le concept d'ingénierie du chaos. Cette approche teste la résilience du système face à des cas extrêmes en injectant des pannes dans un environnement non productif pour atteindre une fiabilité idéale. Selon un article de Gartner, d'ici 2023, 40 % des organisations utiliseront l'ingénierie du chaos pour atteindre leurs principaux objectifs DevOps, réduisant les temps d'arrêt imprévus de 20 %.
C'est exactement ainsi que nous évitons le scénario catastrophe. L'injection de pannes est désormais, à mon avis, incontournable dans toute équipe technique. Dans nos premiers tests, les développeurs arrêtaient un nœud avant de lancer un service pour vérifier si le nœud principal basculait automatiquement vers le secondaire et si la reprise après sinistre fonctionnait.
Mais l'ingénierie du chaos va au-delà de l'injection de pannes. C'est un domaine qui stimule constamment de nouvelles techniques, des outils de test professionnels et des théories solides. Voilà pourquoi nous continuons à l'explorer.
IEG a officiellement lancé son projet d'ingénierie du chaos il y a plus d'un an. Nous voulions faire les choses correctement dès le départ. La clé était de sélectionner un outil d'ingénierie du chaos prenant en charge les expérimentations dans l'environnement Kubernetes. Après une comparaison minutieuse, nous estimons que Chaos Mesh représente notre meilleure option pour ces raisons :
-
C'est un projet Sandbox de la Cloud Native Computing Foundation (CNCF) avec une communauté accueillante et productive.
-
Il n'introduit aucune intrusion dans les applications existantes.
-
Il fournit une interface web et une variété de types d'injection de défaillances, comme illustré ci-dessous.
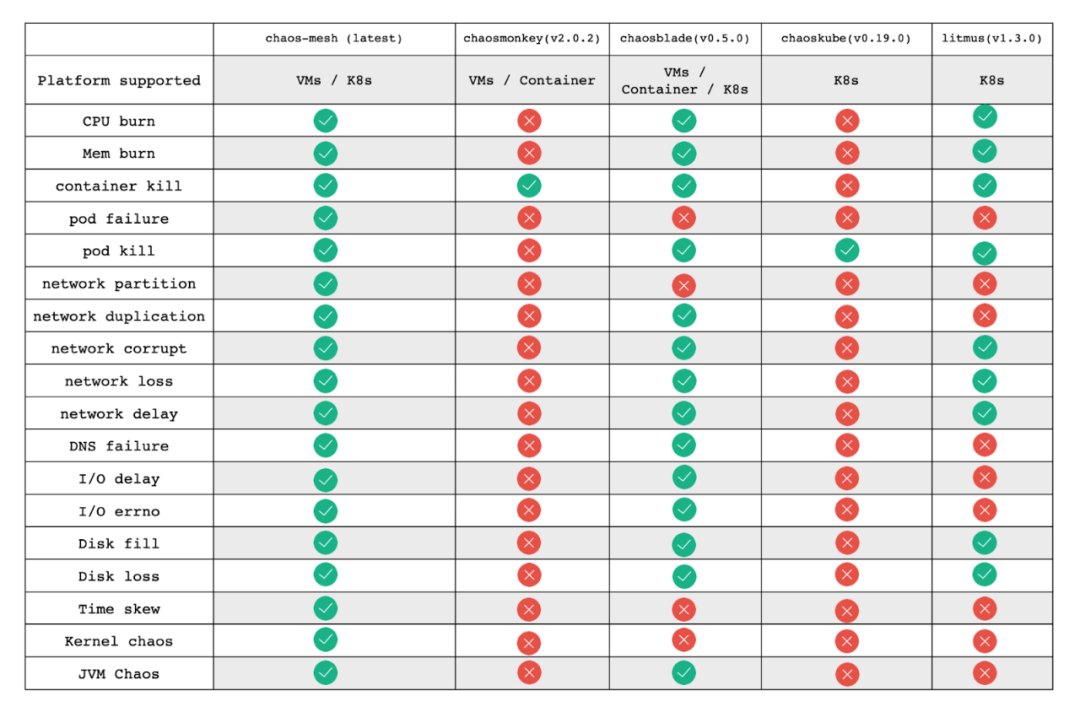
Remarque : Cette comparaison est obsolète et vise simplement à comparer les fonctionnalités d'injection de défaillances prises en charge par Chaos Mesh avec d'autres plateformes d'ingénierie du chaos réputées. Elle n'a pas pour but de favoriser ou positionner un projet par rapport à un autre. Toute correction est bienvenue.
Construire une plateforme de tests chaos
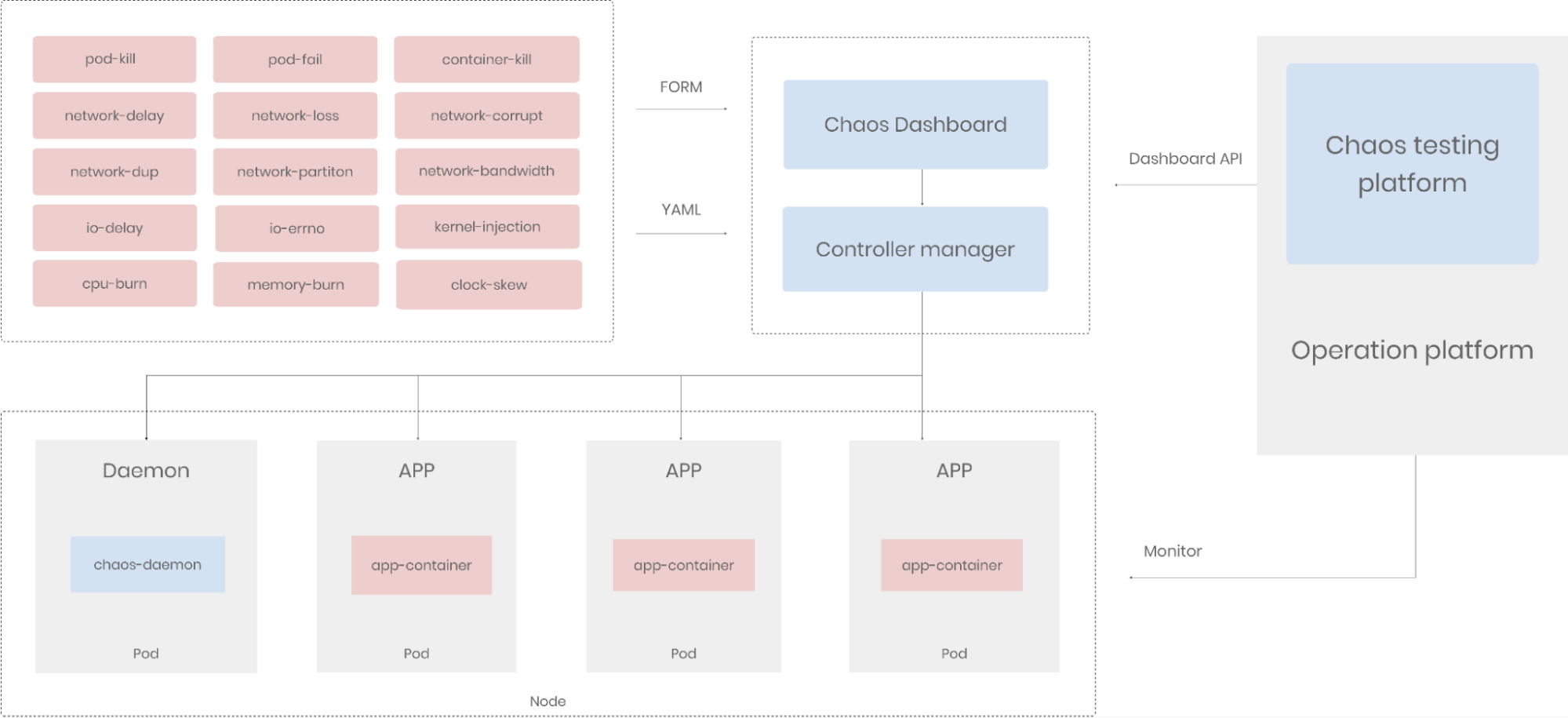
Notre équipe d'ingénierie du chaos a intégré Chaos Mesh dans nos pipelines d'intégration et de livraison continues. Comme illustré ci-dessous, Chaos Mesh joue désormais un rôle crucial dans notre plateforme opérationnelle. Nous utilisons l'API du dashboard de Chaos Mesh pour créer, exécuter et supprimer des expériences chaos tout en les surveillant sur notre propre plateforme. Cela nous permet de simuler des défaillances système de base au niveau des Pods, conteneurs, réseau et E/S.
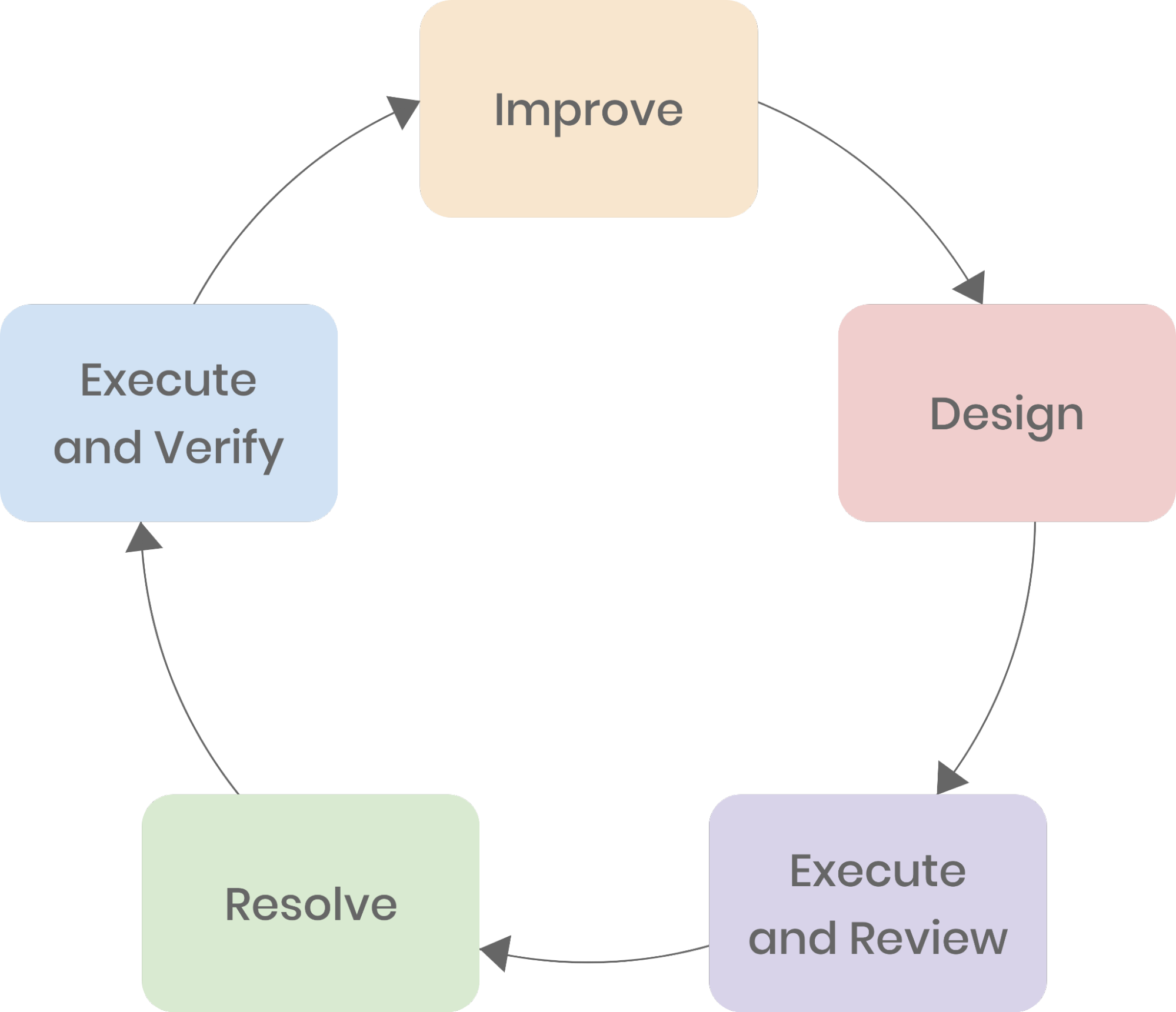
Chez IEG, l'ingénierie du chaos se résume généralement en une boucle fermée avec plusieurs phases clés :
-
Améliorer la résilience globale du système.
Construire une plateforme de tests chaos évolutive selon nos besoins.
-
Concevoir un plan de test.
Le plan doit spécifier la cible, la portée, la défaillance à injecter, les métriques de surveillance, etc. Garantir un contrôle rigoureux des tests.
-
Exécuter les expériences chaos et analyser les résultats.
Comparer les performances du système avant et après l'expérience chaos.
-
Résoudre les problèmes identifiés.
Corriger les anomalies détectées et améliorer le système pour l'expérience suivante.
-
Répéter les expériences chaos et valider les performances.
Répéter les tests pour vérifier si les performances répondent aux attentes. Si c'est le cas, concevoir un nouveau plan de test.
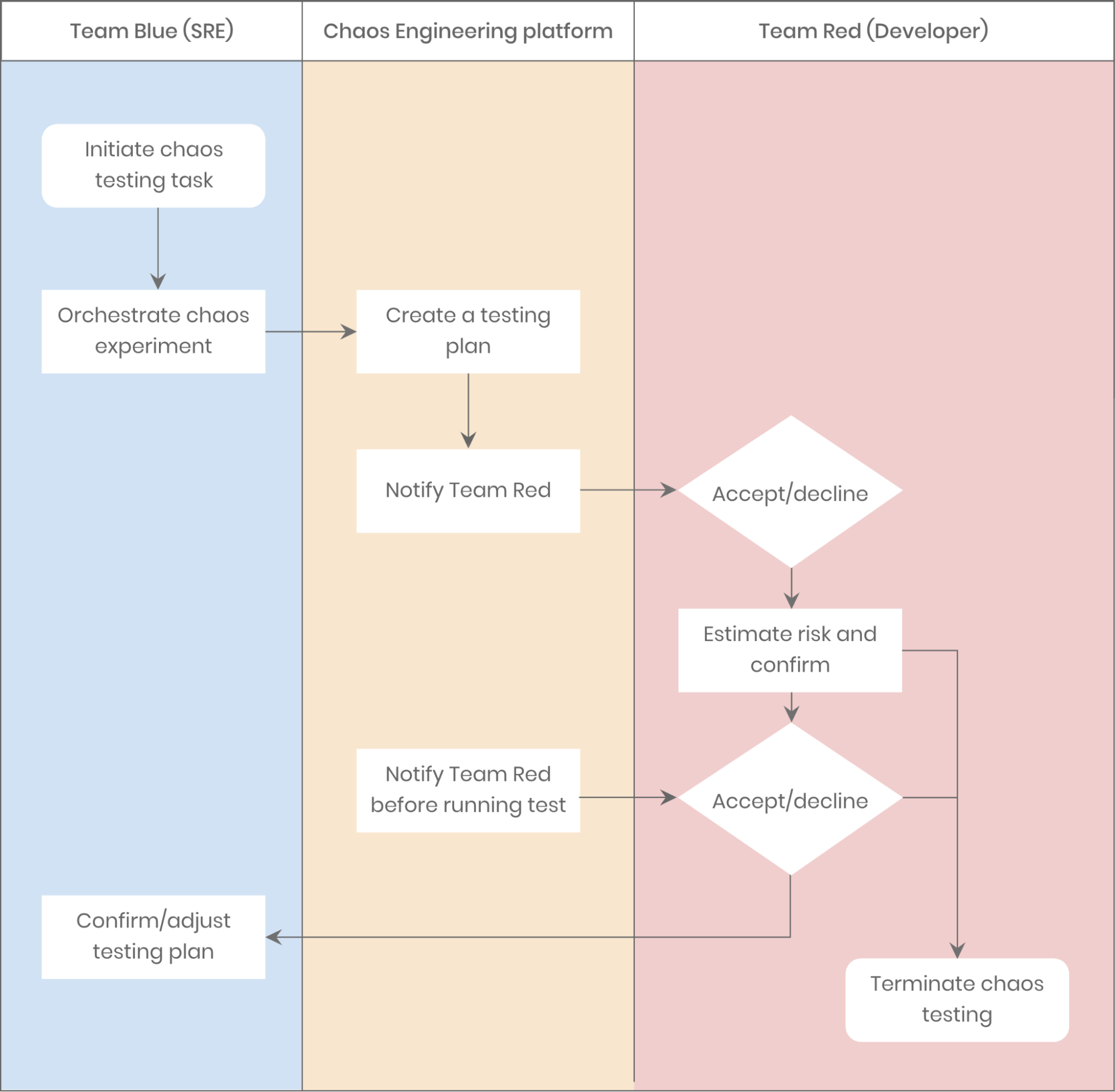
Nous testons fréquemment les performances des services sous forte charge CPU, par exemple. Nous commençons par orchestrer et planifier les expériences. Ensuite, nous exécutons les tests tout en surveillant les performances des services concernés. Des métriques multiples comme le QPS, la latence et le taux de succès des réponses sont visibles en temps réel via la plateforme opérationnelle. Celle-ci génère ensuite des rapports pour analyse, nous permettant de vérifier si les résultats correspondent à nos attentes.
Cas d'utilisation
Voici quelques exemples concrets d'application de l'ingénierie du chaos dans notre flux DevOps.
Granularité fine de l'injection de défaillances
Inutile d'arrêter tout le système pour vérifier la disponibilité de nos jeux. Nous pouvons désormais injecter des défaillances précises (ex : latence réseau) sur un seul compte joueur et observer son comportement. Cette granularité fine est obtenue en détournant le trafic et en exécutant des expériences au niveau de la passerelle.
Red teaming
Comme on peut le comprendre, les membres de notre équipe se sont lassés des expériences de chaos classiques. Après tout, c'est un peu comme demander à sa main gauche de combattre sa main droite. Chez IEG, nous intégrons une pratique de test appelée red teaming à l'ingénierie du chaos pour garantir une amélioration organique de la résilience de notre système. Le red teaming s'apparente aux tests d'intrusion, mais avec une approche plus ciblée. Il implique qu'un groupe de testeurs simule des attaques réelles selon une perspective externe. Si j'étais responsable des opérations IT, je simulerais des pannes sur des services spécifiques pour vérifier si mes collègues développeurs font correctement leur travail. Si je détectais des failles potentielles, préparez-vous à des "discussions musclées". À l'inverse, les développeurs effectueraient activement des expériences de chaos pour s'assurer qu'aucun risque ne subsiste et éviter les reproches.
Analyse des dépendances
La gestion des dépendances est cruciale pour les microservices. Dans notre cas, les services non critiques ne doivent pas devenir un goulot d'étranglement pour les services critiques. Heureusement, l'ingénierie du chaos permet d'effectuer facilement une analyse des dépendances : il suffit d'injecter des pannes dans les services appelés et d'observer leur impact sur le service principal. Sur cette base, nous pouvons optimiser la chaîne d'appel des services dans des scénarios spécifiques.
Détection et diagnostic automatiques des pannes
Nous explorons également l'utilisation de bots IA pour détecter et diagnostiquer les pannes. Plus les services se complexifient, plus les risques de défaillance augmentent. Notre objectif est d'entraîner un modèle de détection des pannes grâce à des expériences de chaos à grande échelle en production ou dans des environnements contrôlés.
L'ingénierie du chaos renforce les pratiques DevOps
Actuellement, en moyenne, plus de 50 personnes exécutent chaque semaine des expériences de chaos, réalisant plus de 150 tests et détectant collectivement plus de 100 problèmes.
Finie l'époque où l'injection de pannes nécessitait des scripts manuscrits, tâche ardue pour les non-initiés. Les avantages du couplage entre ingénierie du chaos et pratiques DevOps sont évidents : en quelques minutes, vous pouvez orchestrer divers types de pannes par simple glisser-déposer, les exécuter d'un clic et surveiller les résultats en temps réel, le tout sur une seule plateforme.
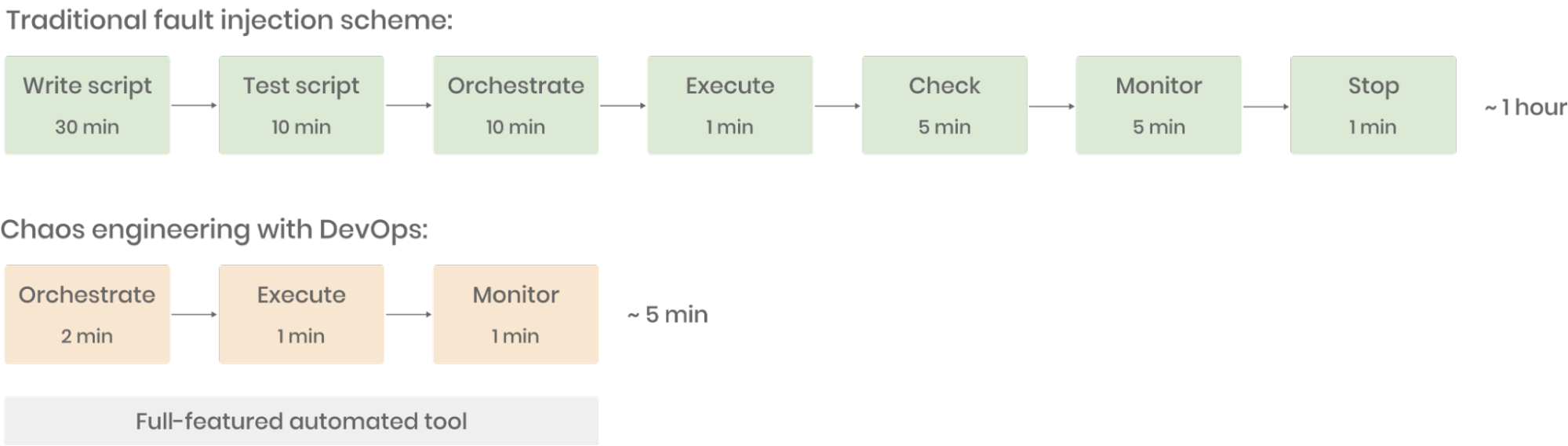
Grâce à des outils d'ingénierie du chaos complets et des processus DevOps rationalisés, nous estimons que l'efficacité de l'injection de pannes et de l'optimisation basée sur le chaos chez IEG a été multipliée par au moins 10 ces six derniers mois. Si vous hésitiez à implémenter l'ingénierie du chaos dans votre entreprise, j'espère que notre expérience vous sera utile.