Chaos Mesh Remake : Un pas de plus vers le Chaos en tant que Service

Cette page a été traduite par PageTurner AI (bêta). Non approuvée officiellement par le projet. Vous avez trouvé une erreur ? Signaler un problème →

Chaos Mesh est une plateforme d'ingénierie du chaos cloud-native qui orchestre le chaos dans des environnements Kubernetes. Avec Chaos Mesh, vous pouvez tester la résilience et la robustesse de votre système sur Kubernetes en injectant différents types de pannes dans les Pods, le réseau, le système de fichiers et même le noyau.
Depuis son open-sourcing et son adoption par la Cloud Native Computing Foundation (CNCF) comme projet sandbox, Chaos Mesh a attiré des contributeurs du monde entier et aidé des utilisateurs à tester leurs systèmes. Cependant, il reste encore des axes d'amélioration :
-
L'utilisabilité doit être améliorée. Certaines fonctionnalités sont complexes à utiliser. Par exemple, lors de l'application d'une expérience de chaos, vous devez souvent vérifier manuellement si l'expérience a démarré.
-
Il est principalement conçu pour les environnements Kubernetes. Comme Chaos Mesh ne peut pas gérer plusieurs clusters Kubernetes, vous devez le déployer pour chaque cluster. Bien que chaosd prenne en charge les expériences sur machines physiques, ses fonctionnalités sont limitées et son utilisation en ligne de commande manque d'ergonomie.
-
Il ne permet pas les extensions. Pour appliquer une expérience de chaos personnalisée, vous devez modifier le code source. De plus, Chaos Mesh ne prend en charge que le Golang.
Certes, Chaos Mesh est une plateforme d'ingénierie du chaos de premier plan, mais il reste encore du chemin avant d'offrir du Chaos en tant que Service (CaaS). C'est pourquoi lors du TiDB Hackathon 2020, nous avons repensé l'architecture de Chaos Mesh, le rapprochant ainsi du CaaS.
Dans cet article, j'expliquerai ce qu'est le CaaS, comment nous l'atteignons avec Chaos Mesh, ainsi que nos plans et enseignements. J'espère que notre expérience vous sera utile pour construire votre propre système d'ingénierie du chaos.
Qu'est-ce que le Chaos en tant que Service ?
Comme l'exprime Matt Fornaciari, cofondateur de Gremlin, le CaaS signifie que "vous bénéficierez d'une interface intuitive, d'un support client, d'intégrations prêtes à l'emploi et de tout ce dont vous avez besoin pour commencer à expérimenter en quelques minutes".
De notre point de vue, le CaaS devrait offrir :
-
Une console unifiée de gestion pour éditer les configurations et créer des expériences de chaos.
-
Des métriques visualisées pour suivre l'état des expériences.
-
Des opérations pour suspendre ou archiver les expériences.
-
Une interaction simplifiée via des actions de glisser-déposer pour orchestrer vos expériences.
Certaines entreprises ont déjà adapté Chaos Mesh à leurs besoins, comme NetEase Fuxi AI Lab et FreeWheel, en faisant une ébauche de CaaS.
Faire évoluer Chaos Mesh vers le CaaS
Basé sur notre compréhension du CaaS, nous avons affiné l'architecture de Chaos Mesh pendant le Hackathon, avec un meilleur support de différents systèmes et une observabilité améliorée. Vous pouvez consulter notre code dans wuntun/chaos-mesh et wuntun/chaosd.
Refonte du Chaos Dashboard
L'architecture actuelle de Chaos Mesh convient à des clusters Kubernetes individuels. Le Chaos Dashboard, l'interface web, est lié à un environnement Kubernetes spécifique :
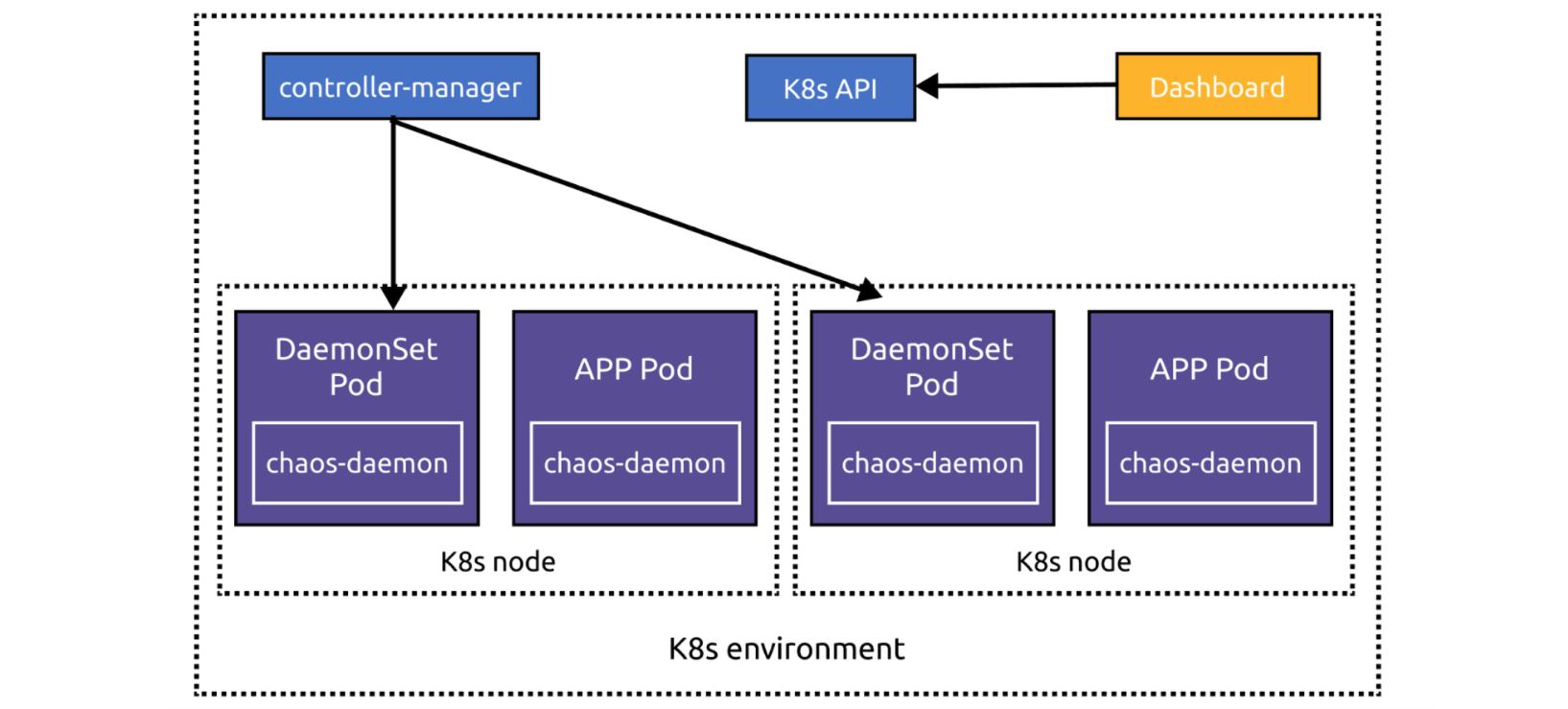
Lors de cette refonte, pour permettre au Chaos Dashboard de gérer plusieurs clusters Kubernetes, nous l'avons dissocié de l'architecture principale. Désormais, si vous déployez Chaos Dashboard en dehors du cluster Kubernetes, vous pouvez ajouter des clusters via l'interface web. Si vous le déployez dans le cluster, il obtient automatiquement les informations via des variables d'environnement.
Vous pouvez enregistrer Chaos Mesh (techniquement, la configuration Kubernetes) dans Chaos Dashboard ou demander à chaos-controller-manager de s'y rapporter via la configuration. Chaos Dashboard et chaos-controller-manager interagissent via des CustomResourceDefinitions (CRDs). Quand chaos-controller-manager détecte un événement CRD Chaos Mesh, il invoque chaos-daemon pour exécuter l'expérience de chaos associée. Ainsi, Chaos Dashboard gère les expériences en manipulant les CRDs.
Refonte de chaosd
chaosd est un outil pour exécuter des expériences de chaos sur machines physiques. Précédemment, il se limitait à une interface en ligne de commande avec des fonctionnalités restreintes.

Lors de la refonte, nous avons doté chaosd d'une API RESTful et amélioré ses services pour qu'il puisse configurer des expériences en analysant des fichiers JSON ou YAML au format CRD.
Désormais, chaosd peut s'enregistrer auprès de Chaos Dashboard via la configuration et envoyer des pulsations régulières. Ces signaux permettent à Chaos Dashboard de gérer l'état des nœuds chaosd. Vous pouvez également ajouter des nœuds chaosd via l'interface web.
De plus, chaosd peut désormais planifier des expériences à des moments précis et gérer leur cycle de vie, unifiant ainsi l'expérience utilisateur entre Kubernetes et les machines physiques.
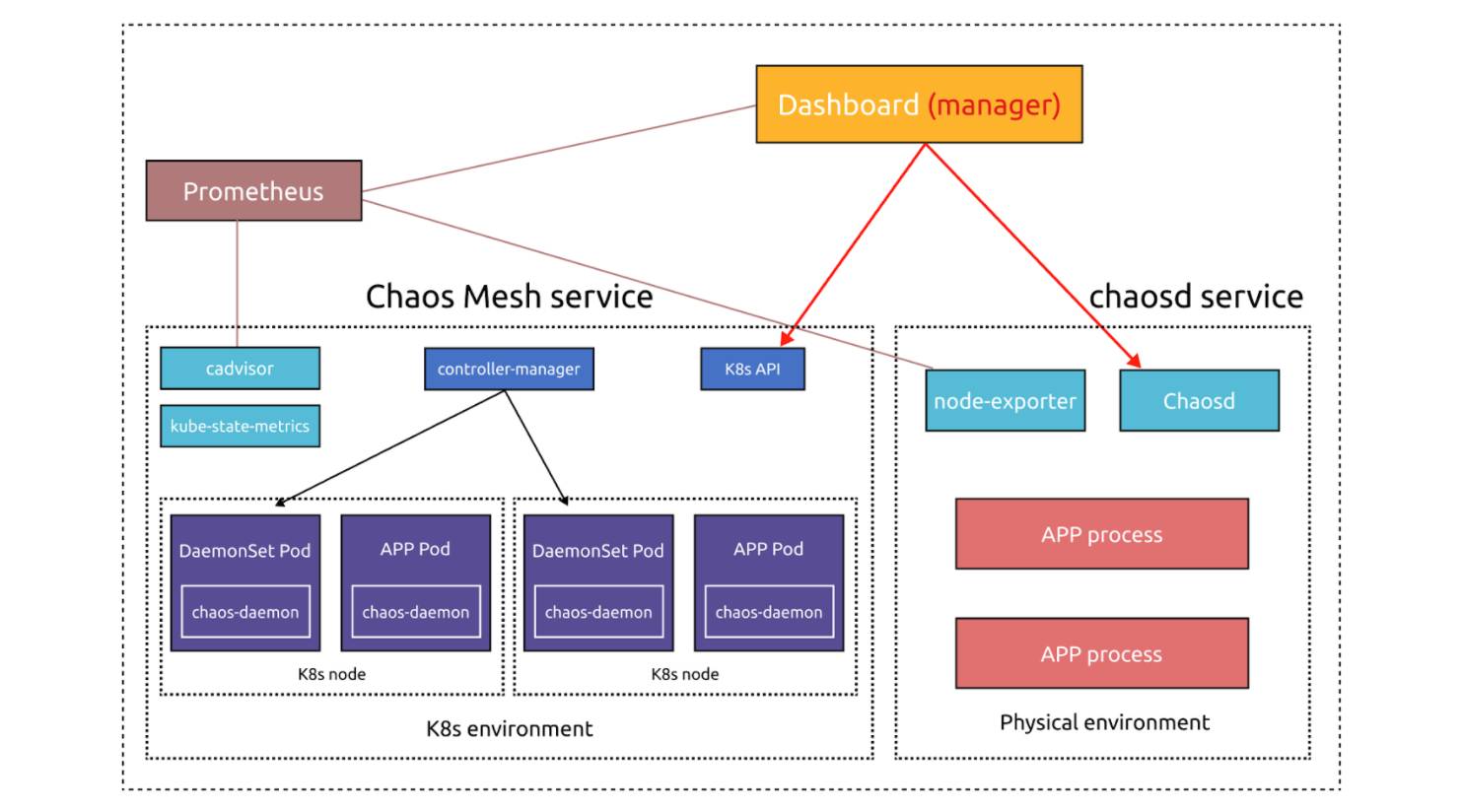
Avec le nouveau Chaos Dashboard et chaosd, l'architecture optimisée de Chaos Mesh est la suivante :
Amélioration de l'observabilité
Une autre amélioration concerne l'observabilité, notamment comment vérifier qu'une expérience s'exécute correctement.
Avant, vous deviez vérifier manuellement les métriques. Si vous injectiez un StressChaos dans un Pod, vous deviez vous y connecter pour vérifier la présence du processus stress-ng puis utiliser des commandes top pour l'utilisation CPU/mémoire. Ces métriques indiquaient si l'expérience StressChaos avait réussi.
Pour simplifier, nous intégrons désormais node_exporter dans chaos-daemon et chaosd pour collecter les métriques des nœuds. Nous déployons aussi kube-state-metrics dans le cluster Kubernetes, combiné avec cadvisor, pour les métriques Kubernetes. Les données sont stockées et visualisées par Prometheus et Grafana, offrant une méthode simple pour vérifier l'état des expériences.
Améliorations supplémentaires nécessaires
Globalement, les métriques visent à vous aider à :
-
Confirmer que le chaos est injecté.
-
Observer l'impact du chaos sur le service et effectuer des analyses périodiques.
-
Réagir aux événements de chaos exceptionnels.
Pour atteindre ces objectifs, le système doit surveiller les métriques des expériences, les métriques standards et les événements. Chaos Mesh doit encore améliorer :
-
Les métriques des expériences, comme la durée exacte d'une latence réseau injectée ou la charge spécifique d'une simulation de charge.
-
Les événements d'expérience, c'est-à-dire les événements Kubernetes de création, suppression et exécution.
Voici un bon exemple de métriques de Litmus.
Autres propositions pour Chaos Mesh
En raison du temps limité lors du Hackathon, nous n'avons pas pu mener à bien tous nos plans. Voici quelques propositions que la communauté Chaos Mesh pourrait envisager à l'avenir.
Orchestration
Une boucle fermée d'ingénierie du chaos comprend quatre étapes : exploration du chaos, identification des lacunes du système, analyse des causes racines et retour d'information pour amélioration.
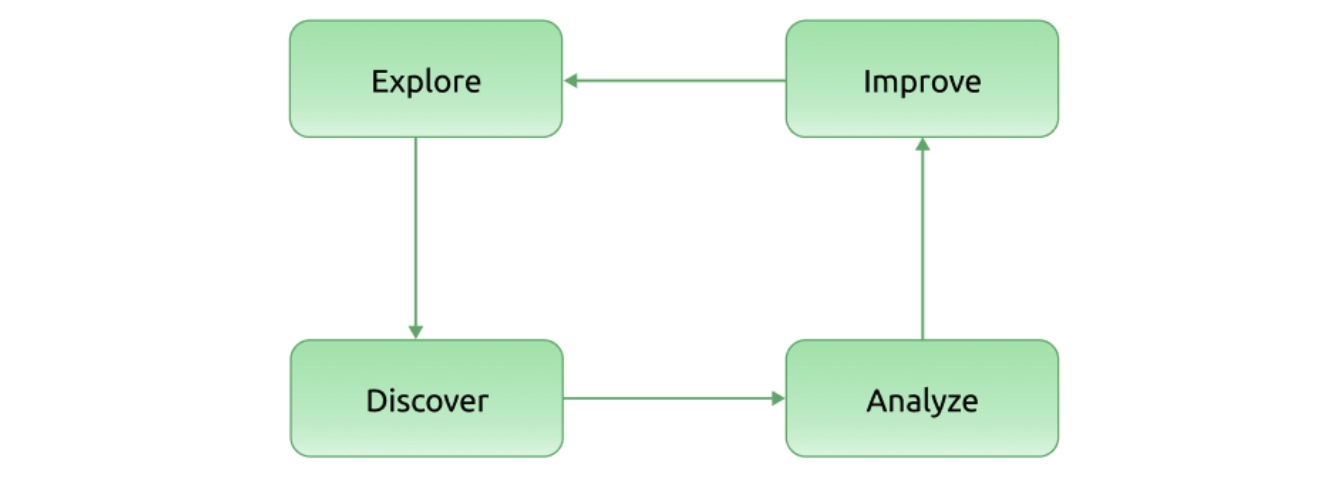
Cependant, la plupart des outils open source actuels d'ingénierie du chaos se concentrent uniquement sur l'exploration et ne fournissent pas de retour pragmatique. Grâce au composant d'observabilité amélioré, nous pouvons surveiller les expériences de chaos en temps réel et comparer/analyser les résultats.
Avec ces résultats, nous pourrons réaliser une boucle fermée en ajoutant un autre composant clé : l'orchestration. La communauté Chaos Mesh a déjà proposé une fonctionnalité Workflow, permettant d'orchestrer et de rappeler facilement des expériences ou d'intégrer Chaos Mesh à d'autres systèmes. Vous pouvez exécuter des expériences pendant les phases CI/CD ou après un déploiement canari.
La combinaison de l'observabilité et de l'orchestration crée une boucle de rétroaction fermée pour l'ingénierie du chaos. Si vous lancez un test de latence réseau de 100 ms sur un Pod, vous pourriez observer le changement de latence via l'observabilité et vérifier la disponibilité du service avec PromQL ou un DSL basé sur l'orchestration. Si le service était indisponible, vous concluriez que le seuil de tolérance est < 100 ms.
Mais 100 ms n'est pas votre seuil critique ; vous devez connaître la latence maximale supportée par votre service. En orchestrant la valeur de l'expérience de chaos, vous découvrirez le seuil à garantir pour vos objectifs de service. Vous évaluerez aussi les performances sous différentes conditions réseau et leur adéquation à vos attentes.
Format des données
Chaos Mesh utilise des CRDs pour définir ses objets de chaos. Si nous convertissons les CRDs en fichiers JSON, nous permettrons la communication entre composants.
Concernant le format, chaosd consomme et enregistre simplement les données CRD au format JSON. Si un outil de chaos peut consommer des données CRD et s'enregistrer, il pourra exécuter des expériences dans divers scénarios.
Plugins
Le support des plugins dans Chaos Mesh est limité. Vous ne pouvez ajouter un nouveau chaos qu'en enregistrant un CRD dans l'API Kubernetes. Cela pose deux problèmes :
-
Vous devez développer le plugin en Golang, le langage de Chaos Mesh.
-
Vous devez fusionner le code étendu dans le projet Chaos Mesh. L'absence de mécanisme de sécurité comme le Berkeley Packet Filter (BPF) introduit des risques lors de l'intégration de code tiers.
Pour un support complet des plugins, nous devons explorer de nouvelles méthodes. Comme Chaos Mesh exécute des expériences via des CRD, une expérience nécessite seulement de générer, écouter et supprimer des CRD. Plusieurs pistes méritent d'être testées :
-
Développer un contrôleur ou opérateur pour gérer les CRDs.
-
Traiter uniformément les événements CRD et les manipuler via des callbacks HTTP. Cette méthode utilise uniquement des APIs HTTP, sans exigence de Golang. Voir l'exemple du Whitebox Controller.
-
Utiliser WebAssembly (Wasm). Pour appeler la logique d'expérience, invoquez simplement le programme Wasm.
-
Utiliser SQL pour interroger l'état des expériences. Comme Chaos Mesh repose sur des CRDs, vous pouvez utiliser SQL pour opérer sur Kubernetes. Par exemple via Presto connector ou osquery extension.
-
Utiliser des extensions basées sur SDK, comme Chaos Toolkit.
Intégration avec d'autres outils de Chaos
Pour les systèmes réels, un seul outil de Chaos Engineering ne peut guère couvrir tous les cas d'utilisation possibles. C'est pourquoi l'intégration avec d'autres outils de chaos peut renforcer considérablement l'écosystème du Chaos Engineering.
Le marché compte de nombreux outils de Chaos Engineering. L'implémentation Kubernetes de Litmus repose sur PowerfulSeal, tandis que son implémentation conteneur utilise Pumba. Kraken se concentre sur Kubernetes, AWSSSMChaosRunner sur AWS, et Toxiproxy cible TCP. On trouve également des projets de fusion basés sur Envoy et Istio.
Pour gérer ces divers outils de chaos, un modèle uniforme comme Chaos Hub pourrait s'avérer nécessaire.
Témoignages de la communauté
Nous souhaitons partager ici comment une entreprise leader en cybersécurité en Chine, utilisatrice de Chaos Mesh, adapte la solution à ses besoins. Leur approche couvre trois aspects : nœud physique, conteneur et application.
Nœud physique
-
Prise en charge de l'exécution de scripts sur serveurs physiques. Vous pouvez configurer le répertoire des scripts dans les CRDs et les exécuter via
chaos-daemon. -
Simulation de redémarrage, d'arrêt et de kernel panic via des scripts personnalisés.
-
Désactivation de la carte réseau (NIC) du nœud à l'aide de scripts personnalisés.
-
Création de changements de contexte fréquents avec sysbench pour simuler l'effet de "voisin bruyant".
-
Interception des appels système du conteneur via
seccompde BPF, en transmettant et filtrant les PID.
Conteneur
-
Modification aléatoire du nombre de réplicas de Deployment pour détecter d'éventuelles anomalies de trafic.
-
Intégration basée sur les objets CRD : remplissage des objets Ingress dans les CRDs de chaos pour simuler une limitation de débit d'interface.
-
Intégration basée sur les objets CRD : remplissage des objets de politique réseau Cilium dans les CRDs de chaos pour simuler des conditions réseau fluctuantes.
Application
-
Prise en charge de l'exécution de jobs personnalisés. Actuellement, Chaos Mesh injecte le chaos via
chaos-daemon, sans garantir l'équité ni l'affinité de planification. Pour résoudre ceci,chaos-controller-managerpeut créer directement des jobs pour différentes CRDs. -
Prise en charge de l'exécution de Newman dans des jobs personnalisés pour modifier aléatoirement des paramètres HTTP. Cela permet d'implémenter des expériences de chaos sur les interfaces HTTP, simulant des comportements utilisateurs exceptionnels.
Conclusion
Les tests de défaillance traditionnels ciblent des points spécifiques du système considérés comme vulnérables. Il s'agit souvent d'une assertion : une condition donnée produit un résultat précis.
Le Chaos Engineering se révèle plus puissant en vous aidant à découvrir les "unknown unknowns". En explorant un domaine plus vaste, il approfondit votre compréhension du système testé et révèle de nouvelles informations.
Pour résumer, voici quelques-unes de nos réflexions et pratiques personnelles sur le Chaos Engineering et Chaos Mesh. Notre projet Hackathon n'est pas encore prêt pour la production, mais nous espérons éclairer le concept de CaaS et esquisser une feuille de route prometteuse pour Chaos Mesh. Si vous êtes intéressé par la construction d'un Chaos as a Service, rejoignez notre Slack (#project-chaos-mesh) !