Chaos Mesh - Votre solution d'ingénierie du chaos pour la résilience des systèmes sur Kubernetes

Cette page a été traduite par PageTurner AI (bêta). Non approuvée officiellement par le projet. Vous avez trouvé une erreur ? Signaler un problème →

Pourquoi Chaos Mesh ?
Dans l'univers du calcul distribué, des défaillances peuvent survenir dans vos clusters de manière imprévisible, n'importe quand et n'importe où. Traditionnellement, nous utilisons des tests unitaires et d'intégration pour garantir qu'un système est prêt pour la production, mais ceux-ci ne couvrent que la partie émergée de l'iceberg à mesure que les clusters grandissent, que les complexités s'accumulent et que les volumes de données atteignent des pétaoctets. Pour mieux identifier les vulnérabilités des systèmes et améliorer leur résilience, Netflix a inventé Chaos Monkey et injecte divers types de défaillances dans l'infrastructure et les systèmes métier. C'est ainsi qu'est née l'ingénierie du chaos.
Chez PingCAP, nous faisons face au même problème lors du développement de TiDB, une base de données NewSQL distribuée open source. La tolérance aux fautes, ou résilience, est particulièrement cruciale pour nous, car l'actif le plus important pour tout utilisateur de base de données - les données elles-mêmes - est en jeu. Pour garantir cette résilience, nous avons commencé à pratiquer l'ingénierie du chaos en interne dès les premières phases de notre cadre de test. Cependant, à mesure que TiDB évoluait, les exigences de test ont également augmenté. Nous avons réalisé avoir besoin d'une plateforme universelle de test du chaos, non seulement pour TiDB mais aussi pour d'autres systèmes distribués.
C'est pourquoi nous vous présentons Chaos Mesh, une plateforme cloud-native d'ingénierie du chaos qui orchestre des expériences de chaos dans des environnements Kubernetes. Il s'agit d'un projet open source disponible sur https://github.com/chaos-mesh/chaos-mesh.
Dans les sections suivantes, je partagerai avec vous ce qu'est Chaos Mesh, comment nous l'avons conçu et implémenté, et enfin je vous montrerai comment l'utiliser dans votre environnement.
Que peut faire Chaos Mesh ?
Chaos Mesh est une plateforme polyvalente d'ingénierie du chaos qui propose des méthodes complètes d'injection de fautes pour les systèmes complexes sur Kubernetes, couvrant les défaillances au niveau des Pods, du réseau, du système de fichiers et même du noyau.
Voici un exemple montrant comment nous utilisons Chaos Mesh pour localiser un bogue système dans TiDB. Dans cet exemple, nous simulons une indisponibilité de Pod avec notre moteur de stockage distribué (TiKV) et observons les variations du nombre de requêtes par seconde (QPS). Normalement, si un nœud TiKV tombe en panne, le QPS peut subir une perturbation transitoire avant de revenir au niveau précédant la défaillance. C'est ainsi que nous garantissons une haute disponibilité.
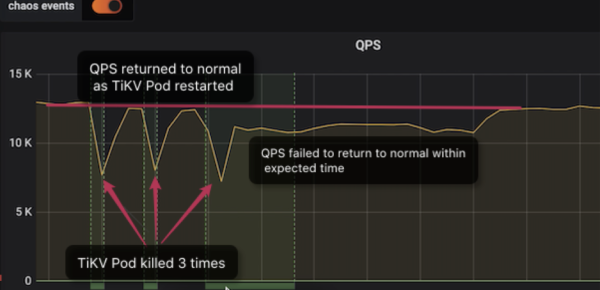
Comme vous pouvez le voir sur le tableau de bord :
-
Lors des deux premières indisponibilités, le QPS revient à la normale en environ 1 minute.
-
Après la troisième indisponibilité en revanche, le QPS met beaucoup plus de temps à se rétablir - environ 9 minutes. Une telle durée d'indisponibilité est inattendue et aurait un impact certain sur les services en ligne.
Après diagnostic, nous avons découvert que la version du cluster TiDB testé (V3.0.1) présentait des problèmes subtils dans la gestion des indisponibilités de TiKV. Nous avons résolu ces problèmes dans les versions ultérieures.
Mais Chaos Mesh peut faire bien plus que simuler des indisponibilités. Il inclut également ces méthodes d'injection de fautes :
-
pod-kill: Simule la suppression de Pods Kubernetes
-
pod-failure: Simule l'indisponibilité prolongée de Pods Kubernetes
-
network-delay: Simule des délais réseau
-
network-loss: Simule des pertes de paquets réseau
-
network-duplication: Simule la duplication des paquets réseau
-
network-corrupt: Simule la corruption des paquets réseau
-
network-partition: Simule une partition réseau
-
I/O delay: Simule les délais d'E/S du système de fichiers
-
I/O errno: Simule les erreurs d'E/S du système de fichiers
Principes de conception
Nous avons conçu Chaos Mesh pour qu'il soit facile à utiliser, évolutif et conçu spécifiquement pour Kubernetes.
Facilité d'utilisation
Pour garantir une utilisation aisée, Chaos Mesh doit :
-
Ne nécessiter aucune dépendance particulière, permettant un déploiement direct sur des clusters Kubernetes, y compris Minikube.
-
Ne pas nécessiter de modifications de la logique de déploiement du système testé (SUT), pour permettre l'exécution d'expériences de chaos en environnement de production.
-
Permettre d'orchestrer facilement les comportements d'injection de fautes dans les expériences de chaos, avec une visualisation claire de l'état et des résultats. Vous devez également pouvoir annuler rapidement les défaillances injectées.
-
Masquer les détails d'implémentation sous-jacents pour que les utilisateurs puissent se concentrer sur l'orchestration des expériences de chaos.
Évolutivité
Chaos Mesh doit être évolutif pour intégrer facilement de nouveaux besoins sans réinventer la roue. Plus précisément, il doit :
-
Tirer parti des implémentations existantes pour permettre une extension aisée des méthodes d'injection de fautes.
-
Faciliter l'intégration avec d'autres cadres de test.
Conçu pour Kubernetes
Dans le monde des conteneurs, Kubernetes est le leader incontesté. Son taux d'adoption dépasse toutes les attentes, et il a remporté la bataille de l'orchestration conteneurisée. Essentiellement, Kubernetes est un système d'exploitation pour le cloud.
TiDB étant une base de données distribuée cloud-native, notre plateforme de tests automatisés internes a été construite sur Kubernetes dès le départ. Des centaines de clusters TiDB y exécutaient quotidiennement diverses expériences, y compris des tests de chaos poussés simulant tous types de défaillances en environnement de production. Pour supporter ces expériences, la combinaison du chaos et Kubernetes s'est imposée comme un choix et un principe d'implémentation naturel.
Conception des CustomResourceDefinitions
Chaos Mesh utilise les CustomResourceDefinitions (CRD) pour définir les objets de chaos. Dans l'écosystème Kubernetes, les CRD sont une solution mature pour implémenter des ressources personnalisées, avec de nombreux cas d'usage et outils disponibles. Cette approche permet à Chaos Mesh de s'intégrer naturellement à l'écosystème Kubernetes.
Plutôt que de définir tous les types d'injections de fautes dans un unique objet CRD, nous autorisons des objets CRD distincts et flexibles pour chaque type d'injection. Si une nouvelle méthode d'injection correspond à un CRD existant, nous l'étendons directement ; s'il s'agit d'une méthode complètement nouvelle, nous créons un nouveau CRD. Cette conception permet une séparation claire entre les définitions d'objets de chaos et leur logique d'implémentation, ce qui clarifie la structure du code. Elle réduit également le couplage et les risques d'erreurs. Par ailleurs, controller-runtime de Kubernetes constitue une excellente abstraction pour implémenter les contrôleurs, nous évitant de réimplémenter la même logique pour chaque projet CRD.
Chaos Mesh implémente les objets PodChaos, NetworkChaos et IOChaos. Leurs noms identifient clairement les types de fautes injectées correspondantes.
Par exemple, les plantages de Pod sont très courants dans Kubernetes. Bien que les ressources natives gèrent généralement ces erreurs (par exemple en créant un nouveau Pod), nos applications y sont-elles réellement préparées ? Que se passe-t-il si le Pod ne redémarre pas ?
Grâce à des actions bien définies comme pod-kill, PodChaos nous aide à identifier efficacement ce type de problèmes. L'objet PodChaos utilise le code suivant :
spec:
action: pod-kill
mode: one
selector:
namespaces:
- tidb-cluster-demo
labelSelectors:
"app.kubernetes.io/component": "tikv"
scheduler:
cron: "@every 2m"
Ce code réalise les actions suivantes :
-
L'attribut
actiondéfinit le type d'erreur à injecter. Ici,pod-killarrête aléatoirement des Pods. -
L'attribut
selectorlimite la portée de l'expérience de chaos à un périmètre spécifique. Ici, il cible les Pods TiKV du cluster TiDB dans le namespacetidb-cluster-demo. -
L'attribut
schedulerdéfinit l'intervalle entre chaque action de perturbation.
Pour plus de détails sur les objets CRD comme NetworkChaos et IOChaos, consultez la documentation Chaos Mesh.
Comment fonctionne Chaos Mesh ?
Maintenant que la conception des CRD est établie, examinons le fonctionnement global de Chaos Mesh. Les composants majeurs impliqués sont :
-
controller-manager
Agit comme le "cerveau" de la plateforme. Il gère le cycle de vie des objets CRD et planifie les expériences de chaos. Il comprend des contrôleurs d'objets pour orchestrer les instances CRD, et le contrôleur admission-webhooks injecte dynamiquement des conteneurs sidecar dans les Pods.
-
chaos-daemon
S'exécute en tant que DaemonSet privilégié pouvant manipuler les périphériques réseau du nœud et le Cgroup.
-
sidecar
S'exécute comme un type spécial de conteneur injecté dynamiquement dans le Pod cible par les admission-webhooks. Par exemple, le conteneur sidecar
chaosfsexécute un fuse-daemon pour intercepter les opérations d'E/S du conteneur d'application.
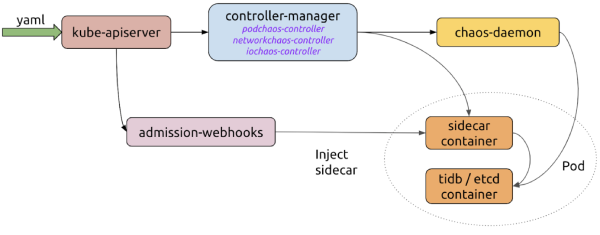
Voici comment ces composants rationalisent une expérience de chaos :
-
Via un fichier YAML ou le client Kubernetes, l'utilisateur crée ou met à jour des objets de chaos sur le serveur d'API Kubernetes.
-
Chaos Mesh utilise le serveur d'API pour surveiller les objets de chaos et gère leur cycle de vie via des événements de création, mise à jour ou suppression. Durant ce processus, controller-manager, chaos-daemon et les conteneurs sidecar collaborent pour injecter des erreurs.
-
Lorsque les admission-webhooks reçoivent une requête de création de Pod, l'objet Pod à créer est mis à jour dynamiquement ; par exemple, en y injectant le conteneur sidecar.
Mise en œuvre du chaos
Les sections précédentes ont présenté la conception et le fonctionnement de Chaos Mesh. Passons maintenant à la pratique pour vous montrer comment l'utiliser. Notez que la durée des tests varie selon la complexité de l'application testée et les règles de planification définies dans le CRD.
Préparation de l'environnement
Chaos Mesh fonctionne sur Kubernetes v1.12 ou ultérieur. Helm, l'outil de gestion de packages Kubernetes, déploie et administre Chaos Mesh. Avant l'exécution, assurez-vous que Helm est correctement installé dans le cluster. Pour configurer l'environnement :
-
Vérifiez que vous disposez d'un cluster Kubernetes. Si c'est le cas, passez à l'étape 2 ; sinon, créez-en un localement avec le script de Chaos Mesh :
// install kind
curl -Lo ./kind https://github.com/kubernetes-sigs/kind/releases/download/v0.6.1/kind-$(uname)-amd64
chmod +x ./kind
mv ./kind /some-dir-in-your-PATH/kind
// get script
git clone https://github.com/chaos-mesh/chaos-mesh
cd chaos-mesh
// start cluster
hack/kind-cluster-build.shRemarque : Un cluster Kubernetes local affecte les injections de fautes réseau.
-
Si votre cluster Kubernetes est prêt, utilisez Helm et Kubectl pour déployer Chaos Mesh :
git clone https://github.com/chaos-mesh/chaos-mesh.git
cd chaos-mesh
// create CRD resource
kubectl apply -f manifests/
// install chaos-mesh
helm install helm/chaos-mesh --name=chaos-mesh --namespace=chaos-meshAttendez que tous les composants soient installés, puis vérifiez l'état de l'installation avec :
// check chaos-mesh status
kubectl get pods --namespace chaos-mesh -l app.kubernetes.io/instance=chaos-meshSi l'installation a réussi, vous verrez tous les pods en cours d'exécution. Il est maintenant temps de tester.
Vous pouvez exécuter Chaos Mesh via une définition YAML ou l'API Kubernetes.
Exécuter le chaos via un fichier YAML
Vous pouvez définir vos propres expériences de chaos via la méthode des fichiers YAML, qui offre un moyen rapide et pratique de mener des expériences de chaos après le déploiement de votre application. Pour exécuter le chaos avec un fichier YAML, suivez ces étapes :
Remarque : À titre d'illustration, nous utilisons TiDB comme système sous test. Vous pouvez choisir le système cible de votre choix et modifier le fichier YAML en conséquence.
-
Déployez un cluster TiDB nommé
chaos-demo-1. Vous pouvez utiliser TiDB Operator pour déployer TiDB. -
Créez le fichier YAML nommé
kill-tikv.yamlavec le contenu suivant :apiVersion: chaos-mesh.org/v1alpha1
kind: PodChaos
metadata:
name: pod-kill-chaos-demo
namespace: chaos-mesh
spec:
action: pod-kill
mode: one
selector:
namespaces:
- chaos-demo-1
labelSelectors:
'app.kubernetes.io/component': 'tikv'
scheduler:
cron: '@every 1m' -
Enregistrez le fichier.
-
Pour démarrer le chaos :
kubectl apply -f kill-tikv.yaml.
Cette expérience de chaos simule la suppression fréquente des Pods TiKV dans le cluster chaos-demo-1 :
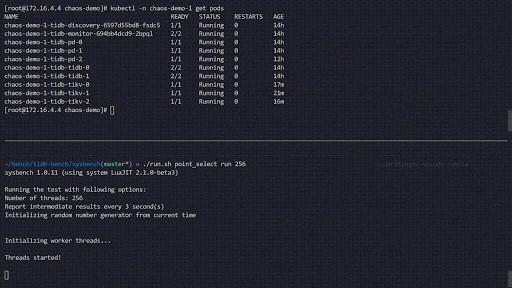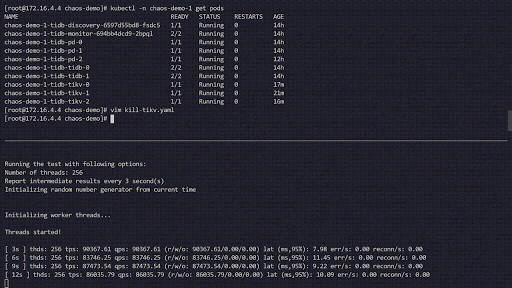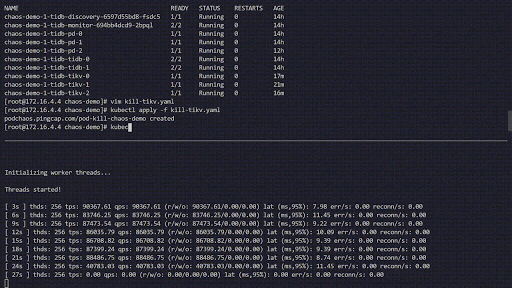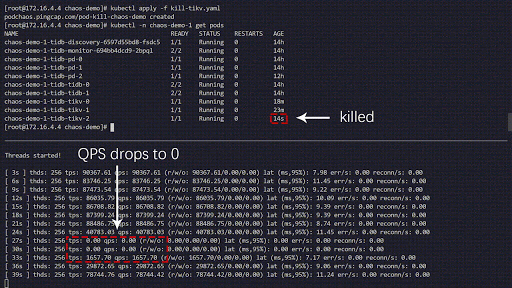
Nous utilisons un programme sysbench pour surveiller les changements en temps réel du QPS dans le cluster TiDB. Lorsque des erreurs sont injectées dans le cluster, le QPS montre une variation brutale, indiquant qu'un Pod TiKV spécifique a été supprimé et que Kubernetes recrée alors un nouveau Pod TiKV.
Pour plus d'exemples de fichiers YAML, consultez https://github.com/chaos-mesh/chaos-mesh/tree/master/examples.
Exécuter le chaos via l'API Kubernetes
Chaos Mesh utilise des CRD pour définir les objets de chaos, vous pouvez donc manipuler directement ces objets CRD via l'API Kubernetes. Cette approche facilite grandement l'application de Chaos Mesh à vos propres applications avec des scénarios de test personnalisés et des expériences de chaos automatisées.
Dans le projet test-infra, nous simulons des erreurs potentielles dans les clusters etcd sur Kubernetes, notamment le redémarrage de nœuds, les pannes réseau et les défaillances du système de fichiers.
Voici un exemple de script Chaos Mesh utilisant l'API Kubernetes :
import (
"context"
"github.com/chaos-mesh/chaos-mesh/api/v1alpha1"
"sigs.k8s.io/controller-runtime/pkg/client"
)
func main() {
// ...
delay := &chaosv1alpha1.NetworkChaos{
Spec: chaosv1alpha1.NetworkChaosSpec{
// ...
},
}
k8sClient := client.New(conf, client.Options{ Scheme: scheme.Scheme })
k8sClient.Create(context.TODO(), delay)
k8sClient.Delete(context.TODO(), delay)
}
Quelles sont les perspectives d'avenir ?
Dans cet article, nous vous avons présenté Chaos Mesh, notre plateforme d'ingénierie du chaos cloud-native open source. De nombreux éléments sont encore en cours de développement, avec davantage de détails à dévoiler concernant la conception, les cas d'usage et l'évolution. Restez à l'écoute.
L'open source n'est qu'un point de départ. En plus des expériences de chaos au niveau infrastructure présentées précédemment, nous travaillons à prendre en charge une plus grande variété de types de fautes avec une granularité plus fine, comme :
-
Injecter des erreurs au niveau des appels système et du noyau grâce à eBPF et d'autres outils
-
Injecter des types d'erreurs spécifiques au niveau des fonctions applicatives et des instructions en intégrant failpoint, couvrant ainsi des scénarios impossibles avec les méthodes d'injection conventionnelles
À l'avenir, nous continuerons d'améliorer le Chaos Mesh Dashboard pour que les utilisateurs puissent facilement observer si et comment leurs applications en production sont impactées par les injections de fautes. Notre feuille de route inclut également une interface d'orchestration des fautes intuitive. Nous prévoyons d'autres fonctionnalités intéressantes comme Chaos Mesh Verifier et Chaos Mesh Cloud.
Si ces projets vous intéressent, rejoignez-nous pour construire une plateforme d'ingénierie du chaos de classe mondiale. Puisse nos applications danser dans le chaos sur Kubernetes !
Si vous rencontrez un bug ou pensez qu'il manque quelque chose, n'hésitez pas à créer une issue, ouvrir une PR ou nous contacter sur le canal #project-chaos-mesh de l'espace CNCF Slack.