Comment développer un système de reporting quotidien pour suivre les résultats des tests de chaos

Cette page a été traduite par PageTurner AI (bêta). Non approuvée officiellement par le projet. Vous avez trouvé une erreur ? Signaler un problème →

Chaos Mesh est une plateforme d'ingénierie du chaos cloud-native qui orchestre des expériences de chaos dans des environnements Kubernetes. Elle vous permet de tester la résilience de votre système en simulant des problèmes tels que des pannes réseau, des défaillances du système de fichiers et des erreurs de Pod. Après chaque expérience de chaos, vous pouvez consulter les résultats des tests en examinant les journaux. Cependant, cette méthode n'est ni directe ni efficace. J'ai donc décidé de développer un système de reporting quotidien qui analyserait automatiquement les journaux et générerait des rapports. Ainsi, il devient facile d'examiner les journaux et d'identifier les problèmes.
Dans cet article, je vais partager avec vous des conseils sur la construction d'un système de reporting quotidien, ainsi que les problèmes rencontrés pendant le processus et la manière dont je les ai résolus.
Déployer Chaos Mesh sur Kubernetes
Chaos Mesh est conçu pour Kubernetes, ce qui est l'une des raisons importantes pour lesquelles il permet aux utilisateurs d'injecter des défaillances dans le système de fichiers, le Pod ou le réseau pour des applications spécifiques.
Dans des documents antérieurs, Chaos Mesh proposait deux méthodes pour déployer rapidement un cluster Kubernetes virtuel sur votre machine : kind et minikube. Généralement, une seule commande suffit pour déployer un cluster Kubernetes et installer Chaos Mesh. Mais il existe quelques problèmes :
-
Le démarrage de clusters Kubernetes en local affecte les types de pannes liées au réseau.
-
Les utilisateurs en Chine continentale peuvent rencontrer un processus d'extraction d'image Docker extrêmement lent, voire un délai d'attente dépassé.
Si vous utilisez le script fourni pour déployer un cluster Kubernetes avec kind, tous les nœuds Kubernetes sont des machines virtuelles (VM). Cela complique l'extraction d'image hors ligne. Pour résoudre ce problème, vous pouvez déployer le cluster Kubernetes sur plusieurs machines physiques, chaque machine physique agissant comme un nœud worker. Pour accélérer le processus d'extraction d'image, utilisez la commande docker load pour charger l'image requise à l'avance. En dehors de ces deux problèmes, vous pouvez installer kubectl et Helm en suivant la documentation.
Note : Pour les dernières instructions d'installation et de déploiement, reportez-vous au Guide de démarrage rapide de Chaos Mesh.
Déployer TiDB
L'étape suivante consiste à déployer TiDB sur Kubernetes. J'ai utilisé TiDB Operator pour simplifier le processus. Pour plus de détails, consultez Premiers pas avec TiDB Operator dans Kubernetes.
Je souhaite souligner deux points dans ce processus :
-
Premièrement, installez les Custom Resource Definitions (CRDs) pour mettre en œuvre les différents composants de TiDB Operator. Sinon, vous obtiendrez des erreurs lors de l'installation de TiDB Operator.
-
Utilisez Longhorn, un système de stockage par blocs distribué pour Kubernetes, pour créer des volumes persistants locaux (PV) pour votre cluster Kubernetes. Ainsi, vous n'avez pas besoin de créer les PV à l'avance : chaque fois qu'un Pod est extrait, un PV est automatiquement créé et monté.
Le plus gros problème que j'ai rencontré était la lenteur extrême de l'extraction d'image lors du déploiement du service. Si les nœuds de votre cluster Kubernetes sont des machines virtuelles, extrayez les images requises à l'avance et chargez-les dans le Docker de chaque machine :
## Pull required images on a machine with a good network connection
docker pull pingcap/tikv:latest
docker pull pingcap/tidb:latest
docker pull pingcap/pd:latest
## Export images and save them to each machine in the Kubernetes cluster
docker save -o tikv.tar pingcap/tikv:latest
docker save -o tidb.tar pingcap/tidb:latest
docker save -o pd.tar pingcap/pd:latest
## Load images to each machine
docker load < tikv.tar
docker load < tidb.tar
docker load < pd.tar
Les commandes ci-dessus vous permettent d'utiliser l'image TiDB dans le registre Docker local pour déployer le dernier cluster TiDB, vous évitant ainsi d'avoir à extraire l'image depuis le dépôt distant. Cette idée s'applique également à l'installation de Chaos Mesh comme décrit précédemment. Si vous ne savez pas quelles images extraire, installez Chaos Mesh avec Helm pour déclencher le processus d'installation, puis utilisez la commande kubectl describe pour vérifier :
## Check pods that are deployed in a specific namespace.
kubectl describe pods -n tidb-test
Le processus de récupération des images prend généralement le plus de temps. Si le Pod est en cours de planification sur un nœud, vérifiez ultérieurement.
Exécuter une expérience de chaos
Pour exécuter une expérience de chaos, vous devez d'abord la définir via des fichiers YAML et utiliser kubectl apply pour la démarrer. Dans cet exemple, j'ai créé une expérience de chaos avec PodChaos pour simuler un crash de Pod. Pour des instructions détaillées, consultez Exécuter une expérience de chaos.
Générer un rapport quotidien
Collecter les logs
Habituellement, lorsque vous exécutez des expériences de chaos sur des clusters TiDB, de nombreuses erreurs sont renvoyées. Pour collecter ces logs d'erreur, exécutez la commande kubectl logs :
kubectl logs <podname> -n tidb-test --since=24h >> tidb.log
Tous les logs générés dans les dernières 24 heures pour le Pod spécifié dans le namespace tidb-test seront sauvegardés dans le fichier tidb.log.
Filtrer les erreurs et avertissements
À cette étape, vous devez filtrer les messages d'erreur et d'avertissement dans les logs. Deux options s'offrent à vous :
-
Utiliser des outils de traitement de texte comme awk. Cela nécessite une maîtrise des commandes Linux/Unix.
-
Écrire un script. Si vous n'êtes pas familier avec les commandes Linux/Unix, c'est l'option la plus adaptée.
Générer un graphique
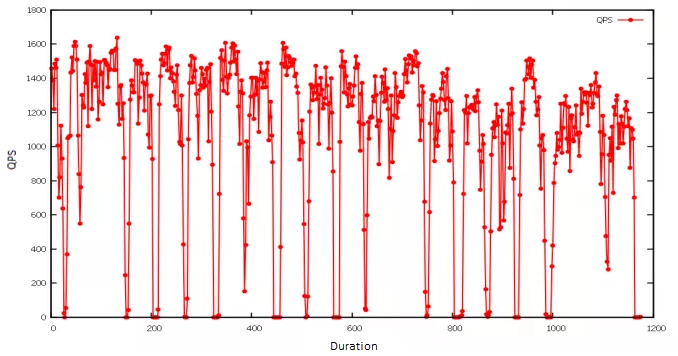
Pour la visualisation graphique, j'ai utilisé gnuplot, un utilitaire de création de graphiques en ligne de commande sous Linux. Dans l'exemple ci-dessous, j'ai importé les résultats des tests de charge et créé un graphique linéaire montrant l'impact sur les requêtes par seconde (QPS) lorsqu'un Pod spécifique devenait indisponible. Comme l'expérience de chaos s'exécutait périodiquement, le nombre de QPS affichait un motif : il chutait brusquement avant de revenir rapidement à la normale.
Générer le rapport en PDF
Actuellement, aucune API n'est disponible pour générer des rapports Chaos Mesh ou analyser les résultats. J'ai choisi de produire le rapport au format PDF pour une lisibilité optimale sur différents navigateurs. Dans mon cas, j'ai utilisé gopdf, une bibliothèque qui permet de créer des fichiers PDF. Elle me permet également d'insérer des images ou de dessiner des tableaux, répondant ainsi à mes besoins.
Pour générer un rapport quotidien, j'ai utilisé crond, un utilitaire qui exécute des tâches cron en arrière-plan, pour lancer les commandes tôt chaque matin. Ainsi, lorsque je commence ma journée de travail, un rapport quotidien m'attend.
Construire une application web pour le reporting quotidien
Mais je souhaitais rendre les rapports plus accessibles et lisibles. Ne serait-il pas préférable de consulter les rapports via une application web ? Initialement, j'envisageais d'ajouter une API backend pour suivre la génération des rapports. Cette approche semble applicable mais représente un travail excessif, car mon objectif principal est d'identifier quels rapports nécessitent un dépannage approfondi. Ces informations sont déjà indiquées dans le nom du fichier, par exemple : report-2021-07-09-bad.pdf. Ainsi, la charge de travail et la complexité du système de reporting sont considérablement réduites.
Il reste nécessaire d'améliorer les interfaces backend et d'enrichir le contenu des rapports. Mais pour l'instant, un système de reporting quotidien opérationnel suffit.
Dans mon cas, j'ai utilisé Vue.js pour structurer l'application web avec la bibliothèque UI antd. Ensuite, j'ai mis à jour le contenu des pages en sauvegardant le rapport généré automatiquement dans le dossier de ressources statiques static. Cela permet à l'application web de lire les rapports statiques et de les afficher sur la page frontale. Pour plus de détails, consultez Utiliser antd avec vue-cli 3.
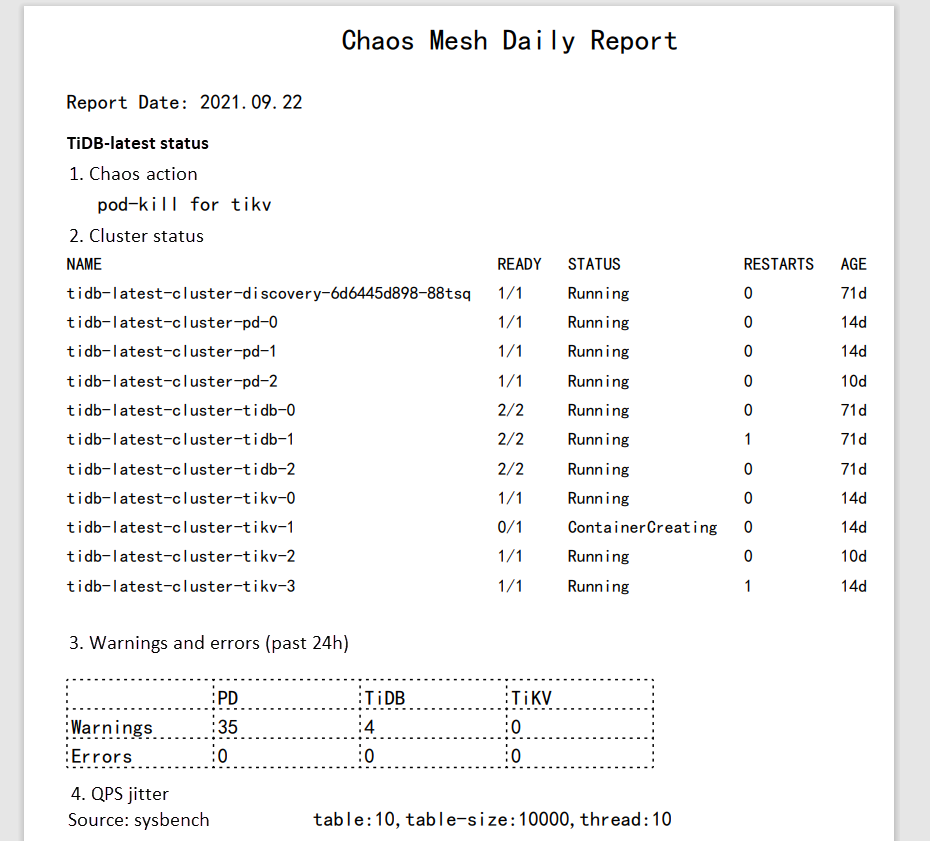
Voici un exemple d'application web que j'ai développée pour le reporting quotidien. La carte rouge indique que je dois examiner le rapport de test car des exceptions sont survenues après l'exécution des expériences de chaos.

Cliquer sur la carte rouge ouvre le rapport, comme illustré ci-dessous. J'ai utilisé pdf.js pour visualiser le PDF.
Conclusion
Chaos Mesh permet de simuler des défaillances que la plupart des applications cloud-natives pourraient rencontrer. Dans cet article, j'ai créé une expérience PodChaos et observé que le QPS du cluster TiDB était affecté lorsque le Pod devenait indisponible. Après analyse des journaux, je peux améliorer la robustesse et la haute disponibilité du système. J'ai développé une application web pour générer des rapports quotidiens de dépannage et de débogage. Vous pouvez également personnaliser ces rapports selon vos besoins spécifiques.
Notre équipe travaille également sur un projet visant à rendre TiDB compatible avec PostgreSQL. Si ce sujet vous intéresse et que vous souhaitez contribuer, n'hésitez pas à choisir une issue et à vous lancer.
Publié initialement sur The New Stack.